
导读: wget是Linux中的一个下载文件的工具,wget是在Linux下开发的开放源代码的软件,作者是Hrvoje Niksic,后来被移植到包括Windows在内的各个平台上。
它用在命令行下。对于Linux用户是必不可少的工具,尤其对于网络管理员,经常要下载一些软件或从远程服务器恢复备份到本地服务器。如果我们使用虚拟主机,处理这样的事务我们只能先从远程服务器下载到我们电脑磁盘,然后再用ftp工具上传到服务器。这样既浪费时间又浪费精力,那不没办法的事。而到了Linux VPS,它则可以直接下载到服务器而不用经过上传这一步。wget工具体积小但功能完善,它支持断点下载功能,同时支持FTP和HTTP下载方式,支持代理服务器和设置起来方便简单。下面我们以实例的形式说明怎么使用wget。
首先安装wget
1 [root@network test]# yum install -y wget
查看帮助手册
1 [root@network test]# wget --help
1 GNU Wget 1.14,非交互式的网络文件下载工具。
2 用法: wget [选项]... [URL]...
3
4 长选项所必须的参数在使用短选项时也是必须的。
5
6 启动:
7 -V, --version 显示 Wget 的版本信息并退出。
8 -h, --help 打印此帮助。
9 -b, --background 启动后转入后台。
10 -e, --execute=COMMAND 运行一个“.wgetrc”风格的命令。
11
12 日志和输入文件:
13 -o, --output-file=FILE 将日志信息写入 FILE。
14 -a, --append-output=FILE 将信息添加至 FILE。
15 -d, --debug 打印大量调试信息。
16 -q, --quiet 安静模式 (无信息输出)。
17 -v, --verbose 详尽的输出 (此为默认值)。
18 -nv, --no-verbose 关闭详尽输出,但不进入安静模式。
19 --report-speed=TYPE Output bandwidth as TYPE. TYPE can be bits.
20 -i, --input-file=FILE 下载本地或外部 FILE 中的 URLs。
21 -F, --force-html 把输入文件当成 HTML 文件。
22 -B, --base=URL 解析与 URL 相关的
23 HTML 输入文件 (由 -i -F 选项指定)。
24 --config=FILE Specify config file to use.
25
26 下载:
27 -t, --tries=NUMBER 设置重试次数为 NUMBER (0 代表无限制)。
28 --retry-connrefused 即使拒绝连接也是重试。
29 -O, --output-document=FILE 将文档写入 FILE。
30 -nc, --no-clobber skip downloads that would download to
31 existing files (overwriting them).
32 -c, --continue 断点续传下载文件。
33 --progress=TYPE 选择进度条类型。
34 -N, --timestamping 只获取比本地文件新的文件。
35 --no-use-server-timestamps 不用服务器上的时间戳来设置本地文件。
36 -S, --server-response 打印服务器响应。
37 --spider 不下载任何文件。
38 -T, --timeout=SECONDS 将所有超时设为 SECONDS 秒。
39 --dns-timeout=SECS 设置 DNS 查寻超时为 SECS 秒。
40 --connect-timeout=SECS 设置连接超时为 SECS 秒。
41 --read-timeout=SECS 设置读取超时为 SECS 秒。
42 -w, --wait=SECONDS 等待间隔为 SECONDS 秒。
43 --waitretry=SECONDS 在获取文件的重试期间等待 1..SECONDS 秒。
44 --random-wait 获取多个文件时,每次随机等待间隔
45 0.5*WAIT...1.5*WAIT 秒。
46 --no-proxy 禁止使用代理。
47 -Q, --quota=NUMBER 设置获取配额为 NUMBER 字节。
48 --bind-address=ADDRESS 绑定至本地主机上的 ADDRESS (主机名或是 IP)。
49 --limit-rate=RATE 限制下载速率为 RATE。
50 --no-dns-cache 关闭 DNS 查寻缓存。
51 --restrict-file-names=OS 限定文件名中的字符为 OS 允许的字符。
52 --ignore-case 匹配文件/目录时忽略大小写。
53 -4, --inet4-only 仅连接至 IPv4 地址。
54 -6, --inet6-only 仅连接至 IPv6 地址。
55 --prefer-family=FAMILY 首先连接至指定协议的地址
56 FAMILY 为 IPv6,IPv4 或是 none。
57 --user=USER 将 ftp 和 http 的用户名均设置为 USER。
58 --password=PASS 将 ftp 和 http 的密码均设置为 PASS。
59 --ask-password 提示输入密码。
60 --no-iri 关闭 IRI 支持。
61 --local-encoding=ENC IRI (国际化资源标识符) 使用 ENC 作为本地编码。
62 --remote-encoding=ENC 使用 ENC 作为默认远程编码。
63 --unlink remove file before clobber.
64
65 目录:
66 -nd, --no-directories 不创建目录。
67 -x, --force-directories 强制创建目录。
68 -nH, --no-host-directories 不要创建主目录。
69 --protocol-directories 在目录中使用协议名称。
70 -P, --directory-prefix=PREFIX 以 PREFIX/... 保存文件
71 --cut-dirs=NUMBER 忽略远程目录中 NUMBER 个目录层。
72
73 HTTP 选项:
74 --http-user=USER 设置 http 用户名为 USER。
75 --http-password=PASS 设置 http 密码为 PASS。
76 --no-cache 不在服务器上缓存数据。
77 --default-page=NAME 改变默认页
78 (默认页通常是“index.html”)。
79 -E, --adjust-extension 以合适的扩展名保存 HTML/CSS 文档。
80 --ignore-length 忽略头部的‘Content-Length’区域。
81 --header=STRING 在头部插入 STRING。
82 --max-redirect 每页所允许的最大重定向。
83 --proxy-user=USER 使用 USER 作为代理用户名。
84 --proxy-password=PASS 使用 PASS 作为代理密码。
85 --referer=URL 在 HTTP 请求头包含‘Referer: URL’。
86 --save-headers 将 HTTP 头保存至文件。
87 -U, --user-agent=AGENT 标识为 AGENT 而不是 Wget/VERSION。
88 --no-http-keep-alive 禁用 HTTP keep-alive (永久连接)。
89 --no-cookies 不使用 cookies。
90 --load-cookies=FILE 会话开始前从 FILE 中载入 cookies。
91 --save-cookies=FILE 会话结束后保存 cookies 至 FILE。
92 --keep-session-cookies 载入并保存会话 (非永久) cookies。
93 --post-data=STRING 使用 POST 方式;把 STRING 作为数据发送。
94 --post-file=FILE 使用 POST 方式;发送 FILE 内容。
95 --content-disposition 当选中本地文件名时
96 允许 Content-Disposition 头部 (尚在实验)。
97 --content-on-error output the received content on server errors.
98 --auth-no-challenge 发送不含服务器询问的首次等待
99 的基本 HTTP 验证信息。
100
101 HTTPS (SSL/TLS) 选项:
102 --secure-protocol=PR choose secure protocol, one of auto, SSLv2,
103 SSLv3, TLSv1, TLSv1_1 and TLSv1_2.
104 --no-check-certificate 不要验证服务器的证书。
105 --certificate=FILE 客户端证书文件。
106 --certificate-type=TYPE 客户端证书类型,PEM 或 DER。
107 --private-key=FILE 私钥文件。
108 --private-key-type=TYPE 私钥文件类型,PEM 或 DER。
109 --ca-certificate=FILE 带有一组 CA 认证的文件。
110 --ca-directory=DIR 保存 CA 认证的哈希列表的目录。
111 --random-file=FILE 带有生成 SSL PRNG 的随机数据的文件。
112 --egd-file=FILE 用于命名带有随机数据的 EGD 套接字的文件。
113
114 FTP 选项:
115 --ftp-user=USER 设置 ftp 用户名为 USER。
116 --ftp-password=PASS 设置 ftp 密码为 PASS。
117 --no-remove-listing 不要删除‘.listing’文件。
118 --no-glob 不在 FTP 文件名中使用通配符展开。
119 --no-passive-ftp 禁用“passive”传输模式。
120 --preserve-permissions 保留远程文件的权限。
121 --retr-symlinks 递归目录时,获取链接的文件 (而非目录)。
122
123 WARC options:
124 --warc-file=FILENAME save request/response data to a .warc.gz file.
125 --warc-header=STRING insert STRING into the warcinfo record.
126 --warc-max-size=NUMBER set maximum size of WARC files to NUMBER.
127 --warc-cdx write CDX index files.
128 --warc-dedup=FILENAME do not store records listed in this CDX file.
129 --no-warc-compression do not compress WARC files with GZIP.
130 --no-warc-digests do not calculate SHA1 digests.
131 --no-warc-keep-log do not store the log file in a WARC record.
132 --warc-tempdir=DIRECTORY location for temporary files created by the
133 WARC writer.
134
135 递归下载:
136 -r, --recursive 指定递归下载。
137 -l, --level=NUMBER 最大递归深度 (inf 或 0 代表无限制,即全部下载)。
138 --delete-after 下载完成后删除本地文件。
139 -k, --convert-links 让下载得到的 HTML 或 CSS 中的链接指向本地文件。
140 --backups=N before writing file X, rotate up to N backup files.
141 -K, --backup-converted 在转换文件 X 前先将它备份为 X.orig。
142 -m, --mirror -N -r -l inf --no-remove-listing 的缩写形式。
143 -p, --page-requisites 下载所有用于显示 HTML 页面的图片之类的元素。
144 --strict-comments 用严格方式 (SGML) 处理 HTML 注释。
145
146 递归接受/拒绝:
147 -A, --accept=LIST 逗号分隔的可接受的扩展名列表。
148 -R, --reject=LIST 逗号分隔的要拒绝的扩展名列表。
149 --accept-regex=REGEX regex matching accepted URLs.
150 --reject-regex=REGEX regex matching rejected URLs.
151 --regex-type=TYPE regex type (posix|pcre).
152 -D, --domains=LIST 逗号分隔的可接受的域列表。
153 --exclude-domains=LIST 逗号分隔的要拒绝的域列表。
154 --follow-ftp 跟踪 HTML 文档中的 FTP 链接。
155 --follow-tags=LIST 逗号分隔的跟踪的 HTML 标识列表。
156 --ignore-tags=LIST 逗号分隔的忽略的 HTML 标识列表。
157 -H, --span-hosts 递归时转向外部主机。
158 -L, --relative 只跟踪有关系的链接。
159 -I, --include-directories=LIST 允许目录的列表。
160 --trust-server-names use the name specified by the redirection
161 url last component.
162 -X, --exclude-directories=LIST 排除目录的列表。
163 -np, --no-parent 不追溯至父目录。
1、使用 wget 下载单个文件
以下的例子是从网络下载一个文件并保存在当前目录
在下载的过程中会显示进度条,包含(下载完成百分比,已经下载的字节,当前下载速度,剩余下载时间)。
1 wget http://cn.wordpress.org/wordpress-4.9.4-zh_CN.tar.gz
2、使用 wget -O 下载并以不同的文件名保存
1 [root@network test]# wget https://cn.wordpress.org/wordpress-4.9.4-zh_CN.tar.gz
2 [root@network test]# ls
3 wordpress-4.9.4-zh_CN.tar.gz
我们可以使用参数-O来指定一个文件名:
1 wget -O wordpress.tar.gz http://cn.wordpress.org/wordpress-4.9.4-zh_CN.tar.gz
2 wordpress.tar.gz
**3、使用 wget -c 断点续传
**
使用wget -c重新启动下载中断的文件:
对于我们下载大文件时突然由于网络等原因中断非常有帮助,我们可以继续接着下载而不是重新下载一个文件
1 wget -c https://cn.wordpress.org/wordpress-4.9.4-zh_CN.tar.gz
4、使用 wget -b 后台下载
对于下载非常大的文件的时候,我们可以使用参数-b进行后台下载
1 [root@network test]# wget -b https://cn.wordpress.org/wordpress-4.9.4-zh_CN.tar.gz
2 继续在后台运行,pid 为 1463。
3 将把输出写入至 “wget-log”。
你可以使用以下命令来察看下载进度
1 [root@network test]# tail -f wget-log
2 8550K .......... .......... .......... .......... .......... 96% 814K 0s
3 8600K .......... .......... .......... .......... .......... 97% 9.53M 0s
4 8650K .......... .......... .......... .......... .......... 98% 86.8M 0s
5 8700K .......... .......... .......... .......... .......... 98% 145M 0s
6 8750K .......... .......... .......... .......... .......... 99% 67.4M 0s
7 8800K .......... .......... .......... .......... .......... 99% 107M 0s
8 8850K .......... ......... 100% 1.95M=16s
9
10 2018-11-10 15:39:07 (564 KB/s) - 已保存 “wordpress-4.9.4-zh_CN.tar.gz.2” [9082696/9082696])
5、伪装代理名称下载
有些网站能通过根据判断代理名称不是浏览器而拒绝你的下载请求。不过你可以通过–user-agent参数伪装。
6、使用 wget –spider 测试下载链接
当你打算进行定时下载,你应该在预定时间测试下载链接是否有效。我们可以增加–spider参数进行检查。
1 wget –spider URL
2 如果下载链接正确,将会显示
3
4 wget –spider URL
5 Spider mode enabled. Check if remote file exists.
6 HTTP request sent, awaiting response… 200 OK
7 Length: unspecified [text/html]
8 Remote file exists and could contain further links,
9 but recursion is disabled — not retrieving.
10 这保证了下载能在预定的时间进行,但当你给错了一个链接,将会显示如下错误
11
12 wget –spider url
13 Spider mode enabled. Check if remote file exists.
14 HTTP request sent, awaiting response… 404 Not Found
15 Remote file does not exist — broken link!!!
你可以在以下几种情况下使用spider参数:
1 定时下载之前进行检查
2 间隔检测网站是否可用
3 检查网站页面的死链接
7、使用 wget –tries 增加重试次数
如果网络有问题或下载一个大文件也有可能失败。wget默认重试20次连接下载文件。如果需要,你可以使用–tries增加重试次数。
1 wget –tries=40 URL
8、使用 wget -i 下载多个文件
1 首先,保存一份下载链接文件
2
3 cat > filelist.txt
4 url1
5 url2
6 url3
7 url4
8 接着使用这个文件和参数-i下载
9
10 wget -i filelist.txt
9、使用 wget –mirror 镜像网站
10、使用 wget –reject 过滤指定格式下载
你想下载一个网站,但你不希望下载图片,你可以使用以下命令。
1 wget –reject=gif url
**11、使用 wget -o 把下载信息存入日志文件
**
你不希望下载信息直接显示在终端而是在一个日志文件,可以使用以下命令:
1 wget -o download.log URL
使用wget -O下载并以不同的文件名保存(-O:下载文件到对应目录,并且修改文件名称)
wget -O wordpress.zip http:``//www``.minjieren.com``/download``.aspx?``id``=1080

使用wget -b后台下载
wget -b <a href=``"http://www.minjieren.com/wordpress-3.1-zh_CN.zip"``>http:``//www``.minjieren.com``/wordpress-3``.1-zh_CN.zip<``/a``>
备注: 你可以使用以下命令来察看下载进度:``tail` `-f wget-log
利用-spider: 模拟下载,不会下载,只是会检查是否网站是否好着
[root@localhost ~]``# wget --spider www.baidu.com #不下载任何文件

模拟下载打印服务器响应
[root@localhost ~]``# wget -S www.baidu.com # 打印服务器响应
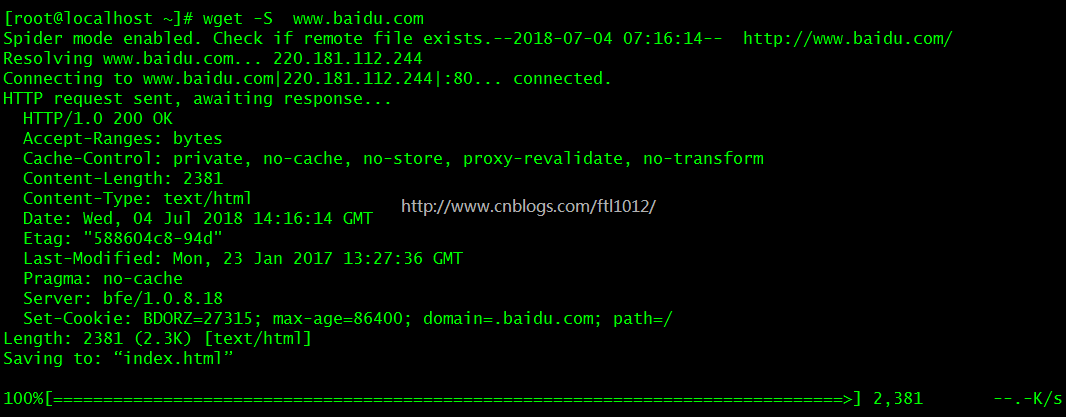
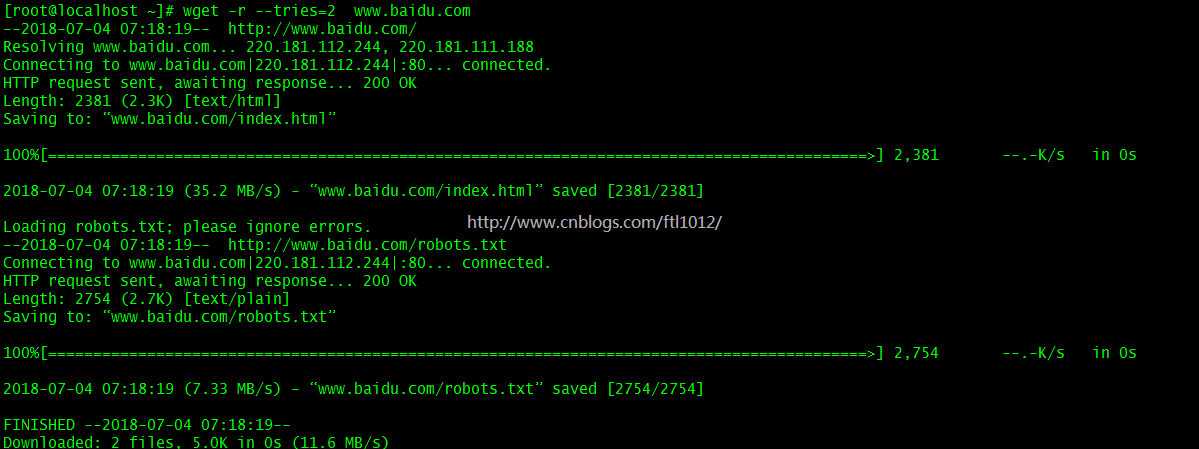
设定指定次数
[root@localhost ~]``# wget -r --tries=2 www.baidu.com (指定尝试2次,2次后不再尝试)`` ``[root@localhost ~]``# wget -r --tries=2 -q www.baidu.com (指定尝试,且不打印中间结果)
版权声明:
本站所有资源均为站长或网友整理自互联网或站长购买自互联网,站长无法分辨资源版权出自何处,所以不承担任何版权以及其他问题带来的法律责任,如有侵权或者其他问题请联系站长删除!站长QQ754403226 谢谢。
- 上一篇: 正确设置网站title、keywords、description(转载)
- 下一篇: URL编码及解码












