
使用Flask-SQLAlchemy管理数据库
Flask-SQLAlchemy是一个Flask扩展,它简化了在Flask应用程序中对SQLAlchemy的使用。SQLAlchemy是一个强大的关系数据库框架,支持一些数据库后端。提供高级的ORM和底层访问数据库的本地SQL功能。
和其他扩展一样,通过pip安装Flask-SQLAlchemy:
(venv) $ pip install flask-sqlalchemy
在Flask-SQLAlchemy,数据库被指定为URL。表格列出三个最受欢迎的数据库引擎url的格式:
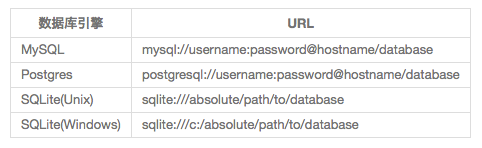
在这些URL中,hostname是指托管MySQL服务的服务器,可能是本地(localhost)又或是远程服务器。数据库服务器可以托管多个数据库,所以database指出要使用的数据库名。数据库需要身份验证,username和 password是数据库用户凭证。
注:> SQLite数据库没有服务,所以hostname、username和password可以缺省且数据库是一个磁盘文件名。
应用程序数据库URL必须在Flask配置对象中的SQLALCHEMY_DATABASE_URI键中进行配置。另一个有用的选项是SQLALCHEMY_COMMIT_ON_TEARDOWN,可以设置为True来启用自动提交数据库更改在每个请求中。查阅Flask-SQLAlchemy文档获取更多其他配置选项。
from flask.ext.sqlalchemy import SQLAlchemy basedir = os.path.abspath(os.path.dirname(__file__)) app = Flask(__name__) app.config['SQLALCHEMY_DATABASE_URI'] =\ 'sqlite:///' + os.path.join(basedir, 'data.sqlite') app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True db = SQLAlchemy(app)
由SQLAlchemy实例化的db对象表示数据库且提供访问Flask-SQLAlchemy的所有功能。
模型定义
模型是指由应用程序使用的持久化实体。在ORM的背景下,一个模型通常是一个带有属性的Python类,其属性与数据库表的列相匹配对应。Flask-SQLAlchemy数据库实例提供了一个基类以及一组辅助类和函数用于定义它的结构。
class Role(db.Model):
__tablename__ = 'roles'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True)
def __repr__(self):
return '<Role %r>' % self.name
class User(db.Model):
__tablename__ = 'users'
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(64), unique=True, index=True)
def __repr__(self):
return '<User %r>' % self.username
__tablename__类变量定义数据库中表的名称。如果__tablename__缺省Flask-SQLAlchemy会指定默认的表名,但是这些缺省名称不遵守使用复数命名的约定,所以最好是显式命名表名。其余的变量是模型的属性,被定义为db.Column类的实例。
传给db.Column构造函数的第一个参数是数据库列的类型也就是模型属性的数据类型。表格5-2列出一些可用的列的类型,也是用于模型中的Python类型。
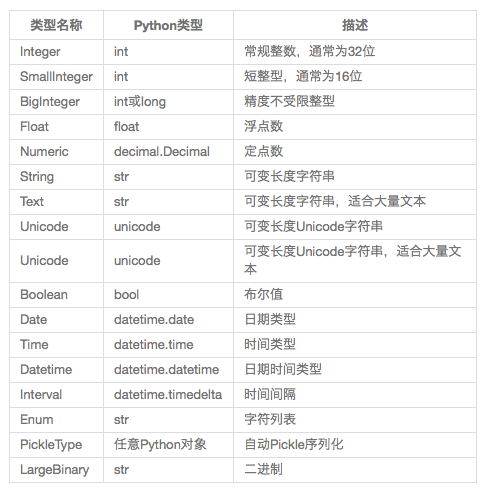
最常见的SQLAlchemy列类型
db.Column剩余的参数为每个属性指定了配置选项。
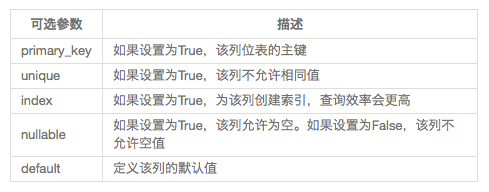
最常见的SQLAlchemy列选项
注:Flask-SQLAlchemy需要给所有的模型定义主键列,通常命名为id。
两个模型都包含了repr()方法来给它们显示一个可读字符串,虽然不是完全必要,不过用于调试和测试还是很不错的。
关系
关系数据库通过使用关系在不同的表中建立连接。关系图表达了用户和用户角色之间的简单关系。这个角色和用户是一对多关系,因为一个角色可以从属于多个用户,而一个用户只能拥有一个角色。
下面的模型类展示了中表达的一对多关系。
class Role(db.Model):
# ...
users = db.relationship('User', backref='role')
class User(db.Model):
# ...
role_id = db.Column(db.Integer, db.ForeignKey('roles.id'))
关系通过使用外键来连接两行。添加给User模型的role_id列被定义为外键,且建立关系。db.ForeignKey()的参数roles.id指定的列应该理解为在roles表的行中持有id值的列。
添加到Role模型的users属性表现了关系的面向对象的观点。给定Role类的实例,users属性会返回一组连接到该角色的用户。指定给db.relationship()的第一个参数表明模型中关系的另一边。如果类还未定义,这个模型可以作为字符串提供。
注意:之前在segmentdefault中遇到的问题,后来粗略阅读了SQLAlchemy的源码。ForeignKey类的column接收三种类型的参数,一种是“模型名.属性名”;一种是“表名.列名”,最后一种没看明白,下次试着用一下。
db.relationship()的backref参数通过给User模型增加role属性来定义反向关系。这个属性可以替代role_id访问Role模型,是作为对象而不是外键。
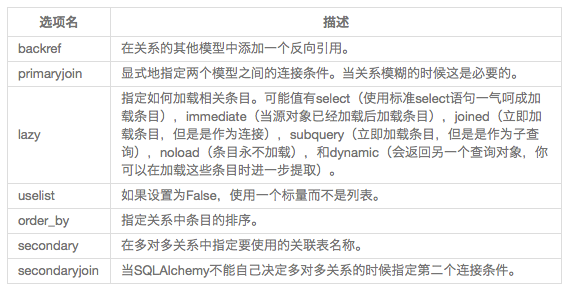
大多数情况下db.relationship()可以定位自己的外键关系,但是有时候不能确定哪个列被用作外键。例如,如果User模型有两个或更多列被定义为Role的外键,SQLAlchemy将不知道使用两个中的哪一个。每当外键配置模棱两可的时候,就必须使用额外参数db.relationship()。下标列出一些常用配置选项用于定义关系:
常用SQLAlchemy关系选项
建议:如果你有克隆在GitHub上的应用程序,你现在可以运行git checkout 5a来切换到这个版本的应用程序。
除了一对多关系还有其他种类关系。一对一关系可以表述为前面描述的一对多关系,只要将db.relationship()中的uselist选项设置为False,“多”就变为“一”了。多对一关系也可表示为将表反转后的一对多关系,或表示为外键和db.relationship()定义在“多”那边。最复杂的关系类型,多对多,需要一个被称作关联表的额外表。你将在第十二章学习多对多关系。
数据库操作
学习怎样使用模型的最好方式就是使用Python shell。以下部分将介绍最常见的数据库操作。
创建表
首先要做的第一件事情就是指示Flask-SQLAlchemy基于模型类创建数据库。db.create_all()函数会完成这些:
(venv) $ python hello.py shell >>> from hello import db >>> db.create_all()
如果你检查应用程序目录,你会发现名为data.sqlite的新文件,SQLite数据库名在配置中给出。如果数据库已存在db.create_all()函数不会重新创建或更新数据库表。这会非常的不方便当模型被修改且更改需要应用到现有的数据库时。更新现有的数据库表的蛮力解决方案是先删除旧的表:
>>> db.drop_all() >>> db.create_all()
不幸的是,这种方法有个不受欢迎的副作用就是摧毁旧的数据库中的所有数据。更新数据库问题的解决方案会在这章快结束的时候介绍。
插入行
下面的示例会创建新的角色和用户:
>>> from hello import Role, User >>> admin_role = Role(name='Admin') >>> mod_role = Role(name='Moderator') >>> user_role = Role(name='User') >>> user_john = User(username='john', role=admin_role) >>> user_susan = User(username='susan', role=user_role) >>> user_david = User(username='david', role=user_role)
模型的构造函数接受模型属性的初始值作为关键字参数。注意,甚至可以使用role属性,即使它不是一个真正的数据库列,而是一对多关系的高级表示。这些新对象的id属性没有显式设置:主键由Flask-SQLAlchemy来管理。到目前为止对象只存于Python中,他们还没有被写入数据库。因为他们的id值尚未分配:
>>> print(admin_role.id) None >>> print(mod_role.id) None >>> print(user_role.id) None
修改数据库的操作由Flask-SQLAlchemy提供的db.session数据库会话来管理。准备写入到数据库中的对象必须添加到会话中:
>>> db.session.add(admin_role) >>> db.session.add(mod_role) >>> db.session.add(user_role) >>> db.session.add(user_john) >>> db.session.add(user_susan) >>> db.session.add(user_david)
或,更简洁的:
>>> db.session.add_all([admin_role, mod_role, user_role, ... user_john, user_susan, user_david])为了写对象到数据库,需要通过它的commit()方法来提交会话:
>>> db.session.commit()
再次检查id属性;这个时候它们都已经被设置好了:
>>> print(admin_role.id) 1 >>> print(mod_role.id) 2 >>> print(user_role.id) 3
注:db.session数据库会话和第四章讨论的Flask会话没有任何联系。数据库会话也叫事务。
数据库会话在数据库一致性上是非常有用的。提交操作会原子性地将所有添加到会话中的对象写入数据库。如果在写入的过程发生错误,会将整个会话丢弃。如果你总是在一个会话提交相关修改,你必须保证避免因部分更新导致的数据库不一致的情况。
注:数据库会话也可以回滚。如果调用db.session.rollback(),任何添加到数据库会话中的对象都会恢复到它们曾经在数据库中的状态。
修改行
数据库会话中的add()方法同样可以用于更新模型。继续在同一shell会话中,下面的示例重命名“Admin”角色为“Administrator”:
>>> admin_role.name = 'Administrator' >>> db.session.add(admin_role) >>> db.session.commit()
注意:不过貌似我们在做更新操作的时候都不使用db.session.add(),而是直接使用db.session.commit()来提交事务。
删除行
数据库会话同样有delete()方法。下面的示例从数据库中删除“Moderator”角色:
>>> db.session.delete(mod_role) >>> db.session.commit()
注意删除,和插入更新一样,都是在数据库会话提交后执行。
返回行
Flask-SQLAlchemy为每个模型类创建一个query对象。最基本的查询模型是返回对应的表的全部内容:
>>> Role.query.all() [<Role u'Administrator'>, <Role u'User'>] >>> User.query.all() [<User u'john'>, <User u'susan'>, <User u'david'>]
使用过滤器可以配置查询对象去执行更具体的数据库搜索。下面的例子查找所有被分配“User”角色的用户:
>>> User.query.filter_by(role=user_role).all() [<User u'susan'>, <User u'david'>]
对于给定的查询还可以检查SQLAlchemy生成的原生SQL查询,并将查询对象转换为一个字符串:
>>> str(User.query.filter_by(role=user_role)) 'SELECT users.id AS users_id, users.username AS users_username, users.role_id AS users_role_id FROM users WHERE :param_1 = users.role_id'
如果你退出shell会话,在前面的示例中创建的对象将不能作为Python对象而存在,但可继续作为行记录存在各自的数据库表中。如果你开始一个全新的shell会话,你必须从它们的数据库行中重新创建Python对象。下面的示例执行查询来加载名字为“User”的用户角色。
>>> user_role = Role.query.filter_by(name='User').first()
过滤器如filter_by()通过query对象来调用,且返回经过提炼后的query。多个过滤器可以依次调用直到需要的查询配置结束为止。
下面展示一些查询中常用的过滤器。

在需要的过滤器已经全部运用于query后,调用all()会触发query执行并返回一组结果,但是除了all()以外还有其他方式可以触发执行。常用SQLAlchemy查询执行器:
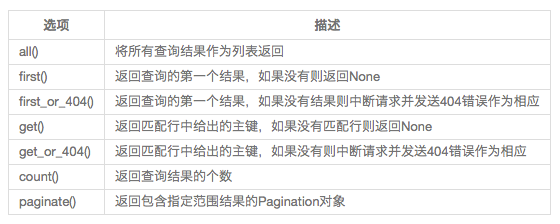
关系的原理类似于查询。下面的示例从两边查询角色和用户之间的一对多关系:
>>> users = user_role.users >>> users [<User u'susan'>, <User u'david'>] >>> users[0].role <Role u'User'>
此处的user_role.users查询有点小问题。当user_role.users表达式在内部调用all()时通过隐式查询执行来返回用户的列表。因为查询对象是隐藏的,是不可能通过附加查询过滤器进一步提取出来。在这个特定的例子中,它可能是用于按字母排列顺序返回用户列表。在下面的示例中,被lazy = 'dynamic'参数修改过的关系配置的查询是不会自动执行的。
app/models.py:动态关系
class Role(db.Model):
# ...
users = db.relationship('User', backref='role', lazy='dynamic')
# ...
用这种方式配置关系,user_roles.user查询还没有执行,所以可以给它增加过滤器:
>>> user_role.users.order_by(User.username).all() [<User u'david'>, <User u'susan'>] >>> user_role.users.count() 2
版权声明:
本站所有资源均为站长或网友整理自互联网或站长购买自互联网,站长无法分辨资源版权出自何处,所以不承担任何版权以及其他问题带来的法律责任,如有侵权或者其他问题请联系站长删除!站长QQ754403226 谢谢。







