
在刚学Pandas时,行选择和列选择非常容易混淆,在这里进行一下讨论和归纳
本文的数据来源:https://github.com/fivethirtyeight/data/tree/master/fandango
import pandas as pd
fandango = pd.read_csv('fandango_score_comparison.csv')
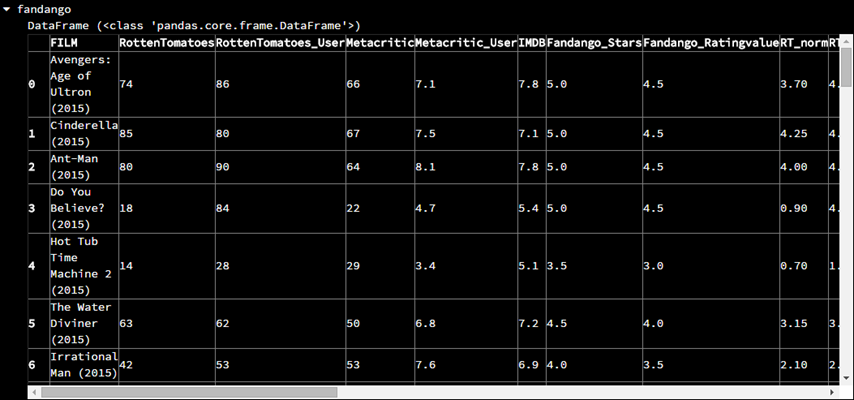
原始的数据如下(截取了一部分)
行选择
Pandas进行行选择一般有三种方法:
- 连续多行的选择用类似于python的列表切片
- 按照指定的索引选择一行或多行,使用loc[]方法
- 按照指定的位置选择一行多多行,使用iloc[]方法
第一种,使用类似于python的列表切片
n = fandango[1:3]

从结果可以看到,和python的列表切片一样,索引号从0开始,选择了索引号1和2的数据(不包括3)
第二种,按照指定的索引选择一行或多行,使用loc[]方法
o = fandango.loc[1] p = fandango.loc[1:3]

可以看到,o是一个Series,选择了索引号为1的那一行数据,注意p,它与第一种的列表索引最大的不同是包含了索引号为3的那一行数据
u = fandango.loc[[1,3]]

这里按照索引号选择不连续的行
第三种,按照指定的位置选择一行多多行,使用iloc[]方法
在上面的数据中,使用iloc[]和loc[]的效果是一样的,因为索引号都是从0开始并且连续不断,现在我要删除索引号为1和2的这两行
fandango_drop = fandango.drop([1,2], axis=0)

可以看到的确删除了两行数据
此时我仍然用loc[]来索引行号为2的那一行,就会出错
s = fandango_drop.loc[2]

但是,我使用iloc[]来进行一次
t = fandango_drop.iloc[2]
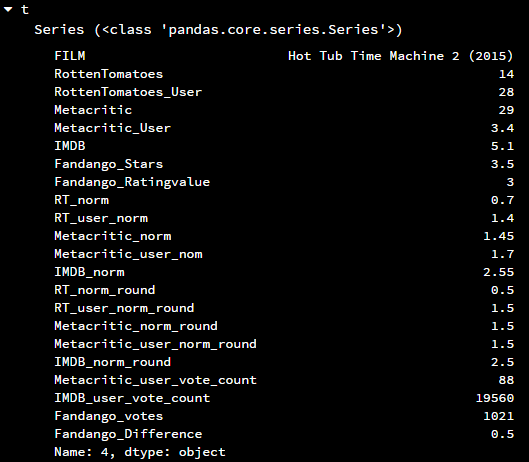
看到了吧,iloc[2]的意思是选择第三行的数据,也就是索引号为4的那一行数据,因为iloc[]的计算也是从0开始的,所以iloc[]适用于数据进行了筛选后造成索引号与原来不一致的情况
loc[]与iloc[]方法之间还有一个巨大的差别,那就是loc[]里的参数是对应的索引值即可,所以参数可以是整数,也可以是字符串。而iloc[]里的参数表示的是第几行的数据,所以只能是整数
列选择
列选择比较简单,只要直接把列名传递过去即可,如果有多列的数据,要单独指出列名或列的索引号
第一种,选择单列,选择了电影名称那一列
q = fandango['FILM']

第二种,通过指定列名选择多列
r = fandango[['FILM','Metacritic']]

第三种,非常容易让人混淆的,通过列的索引号选择多列
v = fandango[[0,1,2]]

其实,列也是有一个索引号的,看到这里不禁想问,那我要选择前5列呢?我不想写一个长列表,又不想逐个写出这5列的名称,能否用切片呢?
x = fandango[[0:5]]

事实证明,这是不行的,更好的方法是在参数中构建一个列表
w = fandango[list(range(5))]
更多的参考资料:http://pandas.pydata.org/pandas-docs/version/0.17.0/api.html
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
版权声明:
本站所有资源均为站长或网友整理自互联网或站长购买自互联网,站长无法分辨资源版权出自何处,所以不承担任何版权以及其他问题带来的法律责任,如有侵权或者其他问题请联系站长删除!站长QQ754403226 谢谢。
- 上一篇: python的几种矩阵相乘的公式详解
- 下一篇: python简单实现矩阵的乘,加,转置和逆运算示例





