
前言
随着人工智能的日益火热,计算机视觉领域发展迅速,尤其在人脸识别或物体检测方向更为广泛,今天就为大家带来最基础的人脸识别基础,从一个个函数开始走进这个奥妙的世界。
首先看一下本实验需要的数据集,为了简便我们只进行两个人的识别,选取了beyond乐队的主唱黄家驹和贝斯手黄家强,这哥俩长得有几分神似,这也是对人脸识别的一个考验:

两个文件夹,一个为训练数据集,一个为测试数据集,训练数据集中有两个文件夹0和1,之前看一些资料有说这里要遵循“slabel”命名规则,但后面处理起来比较麻烦,因为目前opencv接受的人脸识别标签为整数,那我们就直接用整数命名吧:

为了方便,我们每个人用20张照片来训练,0代表黄家驹,1代表黄家强:

开始啦:
1.检测人脸
这应该是最基本的,给我们一张图片,我们要先检测出人脸的区域,然后才能
进行操作,opencv已经内置了很多分类检测器,我们这次用haar:
def detect_face(img):
#将测试图像转换为灰度图像,因为opencv人脸检测器需要灰度图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#加载OpenCV人脸检测分类器Haar
face_cascade = cv2.CascadeClassifier('./haarcascade_frontalface_default.xml')
#检测多尺度图像,返回值是一张脸部区域信息的列表(x,y,宽,高)
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.2, minNeighbors=5)
# 如果未检测到面部,则返回原始图像
if (len(faces) == 0):
return None, None
#目前假设只有一张脸,xy为左上角坐标,wh为矩形的宽高
(x, y, w, h) = faces[0]
#返回图像的正面部分
return gray[y:y + w, x:x + h], faces[0]
2.有了数据集和检测人脸的功能后,我们就可以进行预训练了
最后返回所有训练图片的人脸检测信息和标签:
# 该函数将读取所有的训练图像,从每个图像检测人脸并将返回两个相同大小的列表,分别为脸部信息和标签
def prepare_training_data(data_folder_path):
# 获取数据文件夹中的目录(每个主题的一个目录)
dirs = os.listdir(data_folder_path)
# 两个列表分别保存所有的脸部和标签
faces = []
labels = []
# 浏览每个目录并访问其中的图像
for dir_name in dirs:
# dir_name(str类型)即标签
label = int(dir_name)
# 建立包含当前主题主题图像的目录路径
subject_dir_path = data_folder_path + "/" + dir_name
# 获取给定主题目录内的图像名称
subject_images_names = os.listdir(subject_dir_path)
# 浏览每张图片并检测脸部,然后将脸部信息添加到脸部列表faces[]
for image_name in subject_images_names:
# 建立图像路径
image_path = subject_dir_path + "/" + image_name
# 读取图像
image = cv2.imread(image_path)
# 显示图像0.1s
cv2.imshow("Training on image...", image)
cv2.waitKey(100)
# 检测脸部
face, rect = detect_face(image)
# 我们忽略未检测到的脸部
if face is not None:
#将脸添加到脸部列表并添加相应的标签
faces.append(face)
labels.append(label)
cv2.waitKey(1)
cv2.destroyAllWindows()
#最终返回值为人脸和标签列表
return faces, labels
3.有了脸部信息和对应标签后,我们就可以使用opencv自带的识别器来进行训练了:
#调用prepare_training_data()函数
faces, labels = prepare_training_data("training_data")
#创建LBPH识别器并开始训练,当然也可以选择Eigen或者Fisher识别器
face_recognizer = cv2.face.LBPHFaceRecognizer_create()
face_recognizer.train(faces, np.array(labels))
4.训练完毕后就可以进行预测了
在这之前我们可以设定一下预测的格式,包括用矩形框框出人脸并标出其名字,当然最后别忘了建立标签与真实姓名直接的映射表:
#根据给定的(x,y)坐标和宽度高度在图像上绘制矩形 def draw_rectangle(img, rect): (x, y, w, h) = rect cv2.rectangle(img, (x, y), (x + w, y + h), (128, 128, 0), 2) # 根据给定的(x,y)坐标标识出人名 def draw_text(img, text, x, y): cv2.putText(img, text, (x, y), cv2.FONT_HERSHEY_COMPLEX, 1, (128, 128, 0), 2) #建立标签与人名的映射列表(标签只能为整数) subjects = ["jiaju", "jiaqiang"]
5.现在就可以定义我们的预测函数了:
# 此函数识别传递的图像中的人物并在检测到的脸部周围绘制一个矩形及其名称 def predict(test_img): #生成图像的副本,这样就能保留原始图像 img = test_img.copy() #检测人脸 face, rect = detect_face(img) #预测人脸 label = face_recognizer.predict(face) # 获取由人脸识别器返回的相应标签的名称 label_text = subjects[label[0]] # 在检测到的脸部周围画一个矩形 draw_rectangle(img, rect) # 标出预测的名字 draw_text(img, label_text, rect[0], rect[1] - 5) #返回预测的图像 return img
6.最后使用我们test_data中的图片进行预测并显示最终效果:
#加载测试图像
test_img1 = cv2.imread("test_data/test1.jpg")
test_img2 = cv2.imread("test_data/test2.jpg")
#执行预测
predicted_img1 = predict(test_img1)
predicted_img2 = predict(test_img2)
#显示两个图像
cv2.imshow(subjects[0], predicted_img1)
cv2.imshow(subjects[1], predicted_img2)
cv2.waitKey(0)
cv2.destroyAllWindows()
来看看识别的结果:
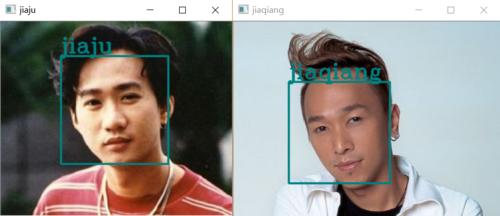
这就是人脸识别最基本的流程,后续还会进一步的研究,下一篇我们将讨论本次实验的一些细节和注意事项,算是对本篇的一次挖掘和总结吧。
最后附上完整代码:
# # -*- coding:utf-8 -*-
import cv2
import os
import numpy as np
# 检测人脸
def detect_face(img):
#将测试图像转换为灰度图像,因为opencv人脸检测器需要灰度图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#加载OpenCV人脸检测分类器Haar
face_cascade = cv2.CascadeClassifier('./haarcascade_frontalface_default.xml')
#检测多尺度图像,返回值是一张脸部区域信息的列表(x,y,宽,高)
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.2, minNeighbors=5)
# 如果未检测到面部,则返回原始图像
if (len(faces) == 0):
return None, None
#目前假设只有一张脸,xy为左上角坐标,wh为矩形的宽高
(x, y, w, h) = faces[0]
#返回图像的正面部分
return gray[y:y + w, x:x + h], faces[0]
# 该函数将读取所有的训练图像,从每个图像检测人脸并将返回两个相同大小的列表,分别为脸部信息和标签
def prepare_training_data(data_folder_path):
# 获取数据文件夹中的目录(每个主题的一个目录)
dirs = os.listdir(data_folder_path)
# 两个列表分别保存所有的脸部和标签
faces = []
labels = []
# 浏览每个目录并访问其中的图像
for dir_name in dirs:
# dir_name(str类型)即标签
label = int(dir_name)
# 建立包含当前主题主题图像的目录路径
subject_dir_path = data_folder_path + "/" + dir_name
# 获取给定主题目录内的图像名称
subject_images_names = os.listdir(subject_dir_path)
# 浏览每张图片并检测脸部,然后将脸部信息添加到脸部列表faces[]
for image_name in subject_images_names:
# 建立图像路径
image_path = subject_dir_path + "/" + image_name
# 读取图像
image = cv2.imread(image_path)
# 显示图像0.1s
cv2.imshow("Training on image...", image)
cv2.waitKey(100)
# 检测脸部
face, rect = detect_face(image)
# 我们忽略未检测到的脸部
if face is not None:
#将脸添加到脸部列表并添加相应的标签
faces.append(face)
labels.append(label)
cv2.waitKey(1)
cv2.destroyAllWindows()
#最终返回值为人脸和标签列表
return faces, labels
#调用prepare_training_data()函数
faces, labels = prepare_training_data("training_data")
#创建LBPH识别器并开始训练,当然也可以选择Eigen或者Fisher识别器
face_recognizer = cv2.face.LBPHFaceRecognizer_create()
face_recognizer.train(faces, np.array(labels))
#根据给定的(x,y)坐标和宽度高度在图像上绘制矩形
def draw_rectangle(img, rect):
(x, y, w, h) = rect
cv2.rectangle(img, (x, y), (x + w, y + h), (128, 128, 0), 2)
# 根据给定的(x,y)坐标标识出人名
def draw_text(img, text, x, y):
cv2.putText(img, text, (x, y), cv2.FONT_HERSHEY_COMPLEX, 1, (128, 128, 0), 2)
#建立标签与人名的映射列表(标签只能为整数)
subjects = ["jiaju", "jiaqiang"]
# 此函数识别传递的图像中的人物并在检测到的脸部周围绘制一个矩形及其名称
def predict(test_img):
#生成图像的副本,这样就能保留原始图像
img = test_img.copy()
#检测人脸
face, rect = detect_face(img)
#预测人脸
label = face_recognizer.predict(face)
# 获取由人脸识别器返回的相应标签的名称
label_text = subjects[label[0]]
# 在检测到的脸部周围画一个矩形
draw_rectangle(img, rect)
# 标出预测的名字
draw_text(img, label_text, rect[0], rect[1] - 5)
#返回预测的图像
return img
#加载测试图像
test_img1 = cv2.imread("test_data/test1.jpg")
test_img2 = cv2.imread("test_data/test2.jpg")
#执行预测
predicted_img1 = predict(test_img1)
predicted_img2 = predict(test_img2)
#显示两个图像
cv2.imshow(subjects[0], predicted_img1)
cv2.imshow(subjects[1], predicted_img2)
cv2.waitKey(0)
cv2.destroyAllWindows()
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
版权声明:
本站所有资源均为站长或网友整理自互联网或站长购买自互联网,站长无法分辨资源版权出自何处,所以不承担任何版权以及其他问题带来的法律责任,如有侵权或者其他问题请联系站长删除!站长QQ754403226 谢谢。
- 上一篇: PowerBI和Python关于数据分析的对比
- 下一篇: python实现微信自动回复机器人功能






