
match()函数的使用。以及从文本中提取数据的方法。在学习re模块的相关函数前应了解正则表达式的特殊字符
准备一个要爬取的文本文档:
直接从某个网页拷贝一份代码,粘贴在 一个txt文件里,以供学习。
方法很简单,比如打开百度视频的热门电影网页,右键点击查看源代码,然后复制,粘贴到一个txt文件里,保存到工作目录下。
有4000多行。
re.match(pattern, string, flags=0)
①pattern,是正则表达式。string,被检验的字符串。
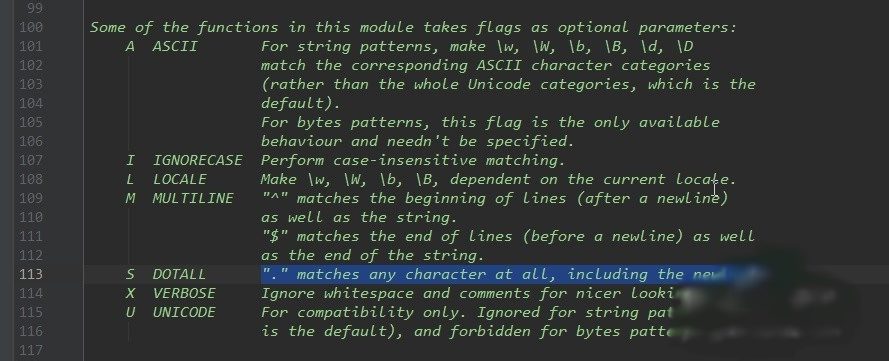
②flags是可选参数,此标记是用来对patten的补充。例如:re.S,可以让正则表达式中的点匹配换行符\n。(如图片中,可以看帮助文档,查看有哪些标记)
③ match()函数由左向右检验string,若匹配到正则表达式,返回一个匹配对象,否则就返回None.
④re.match() 匹配字符串的开始位置,而不匹配每行开始。
----所以才将网页的每行放入列表,以供match函数对每行操作。
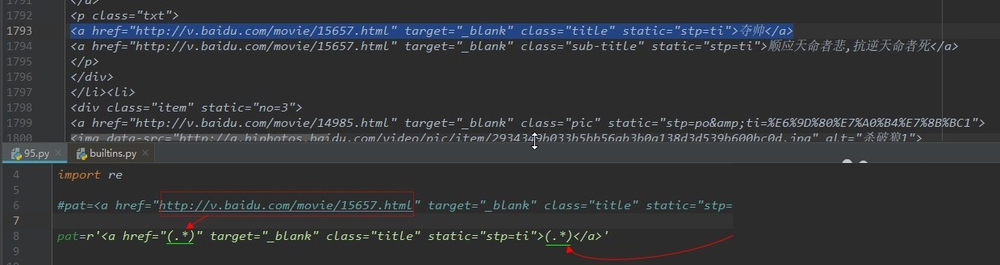
比如要在文档中,提取电影的网址,和电影名。
①复制那行文本作为表达式,
②将要提取的网址和和电影名替换为(.*),这只是暂时的,可以在接下来的代码中调整。
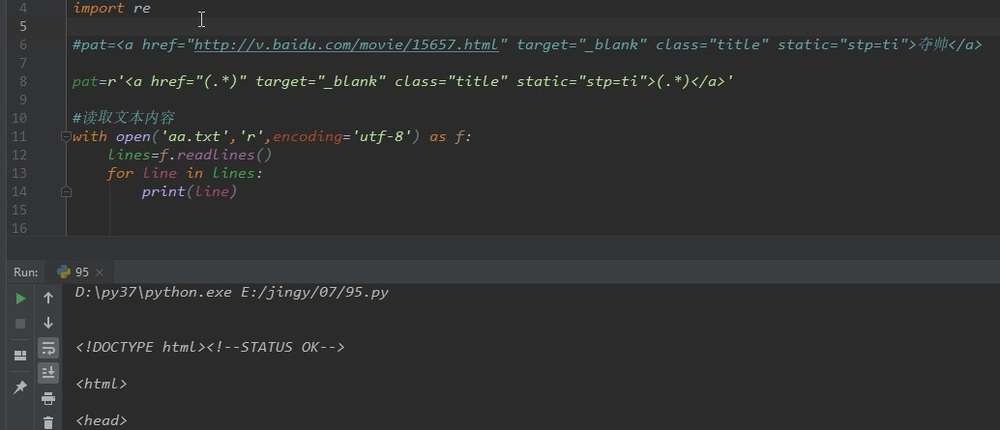
读取文本:
①用with open()语句读取;
②用readlines,一次性读完,返回一个列表,元素是文本的每一行。
with open('aa.txt','r',encoding='utf-8') as f:
lines=f.readlines()
①判断每行是否返回了匹配的对象,
②接收匹配对象,并用groups()提取表达式内括号的内容;
for line in lines:
if re.match(pat,line): #判断过滤掉返回None的行,
ret=re.match(pat,line) #接收匹配对象
print(ret.groups())
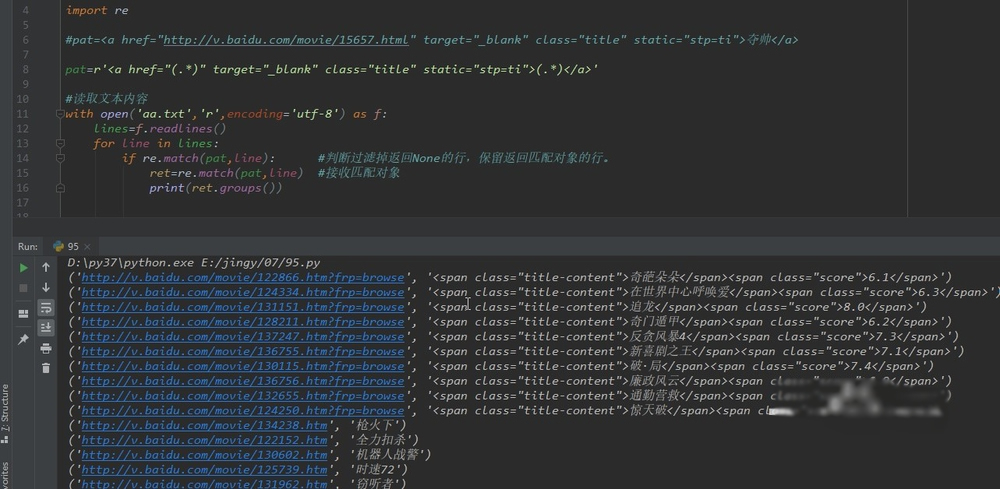
发现有不符合的行,稍加修改,过滤掉不符合的行:
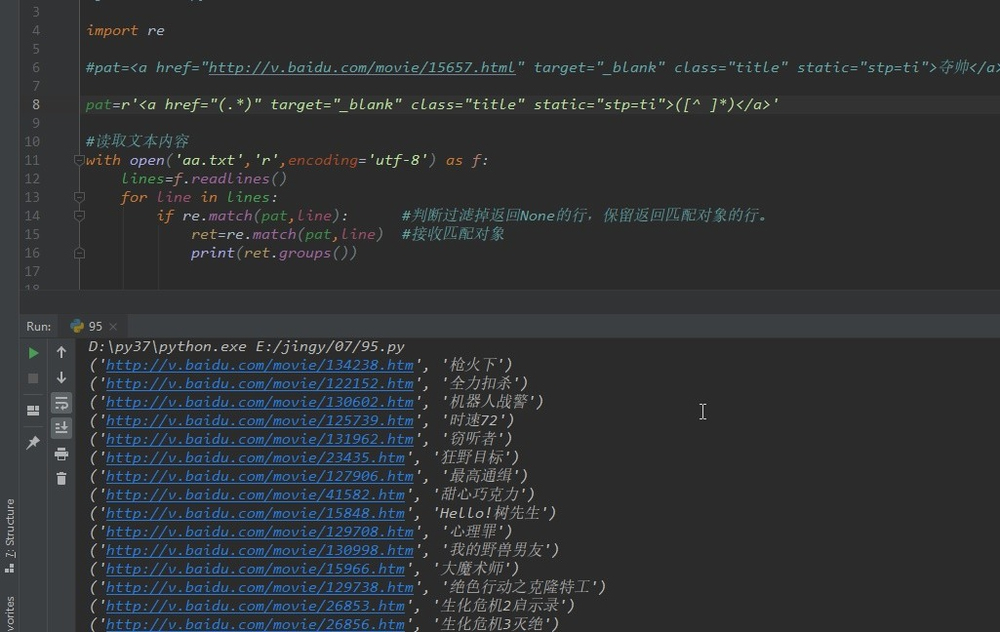
因为,不合的行都有空格(或其他字符)。可以给第二子组的点 . 换成非[^ ];非空格的任意字符,意思就是不要有空格的。
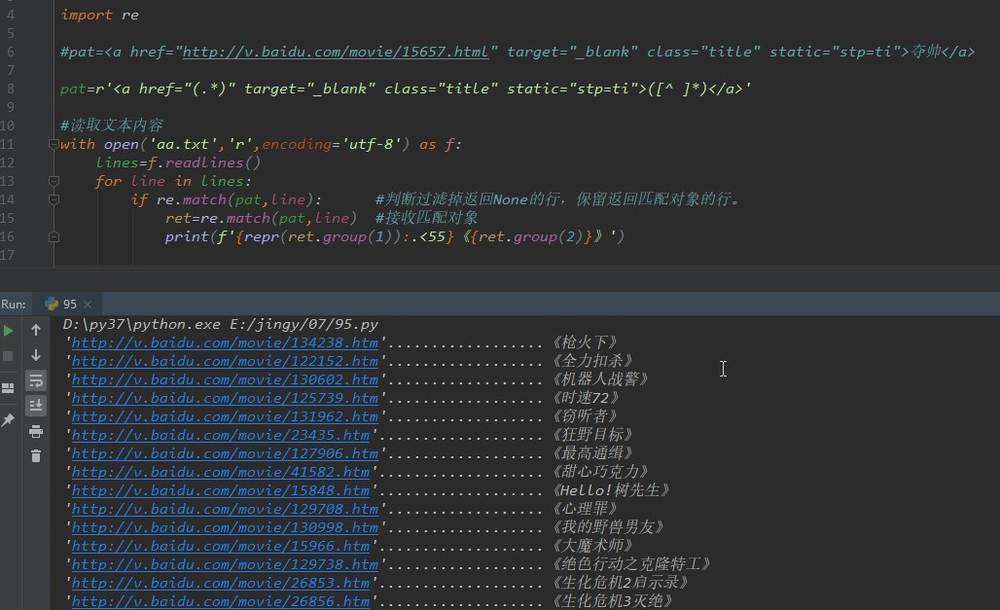
用f-string格式化对输出的文本稍加修饰,使用group(1),group(2);
可以将这段代码封装为一个函数。爬取百度视频的其他栏目。
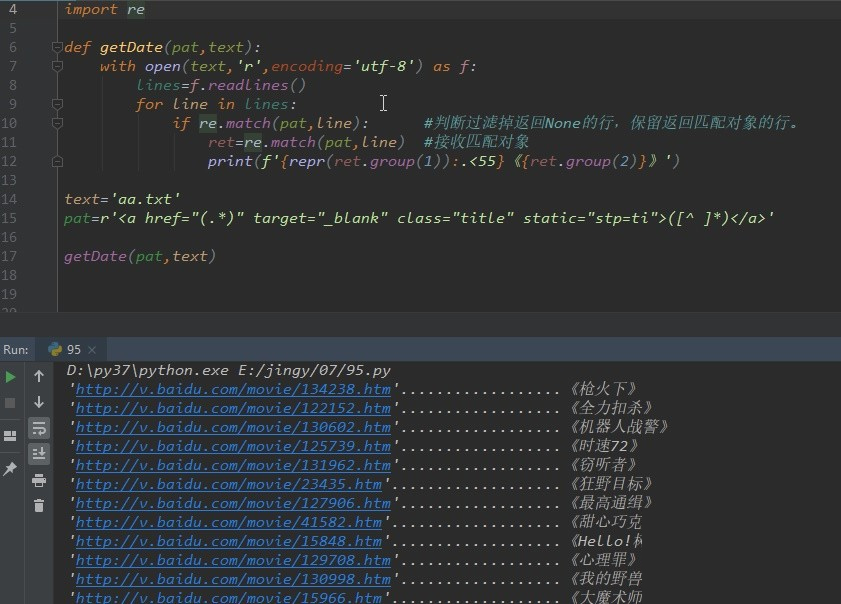
测试: 百度视频的电影,电视剧,和动漫等栏目,网页上的格式基本相同,所以用上面的函数直接套用。
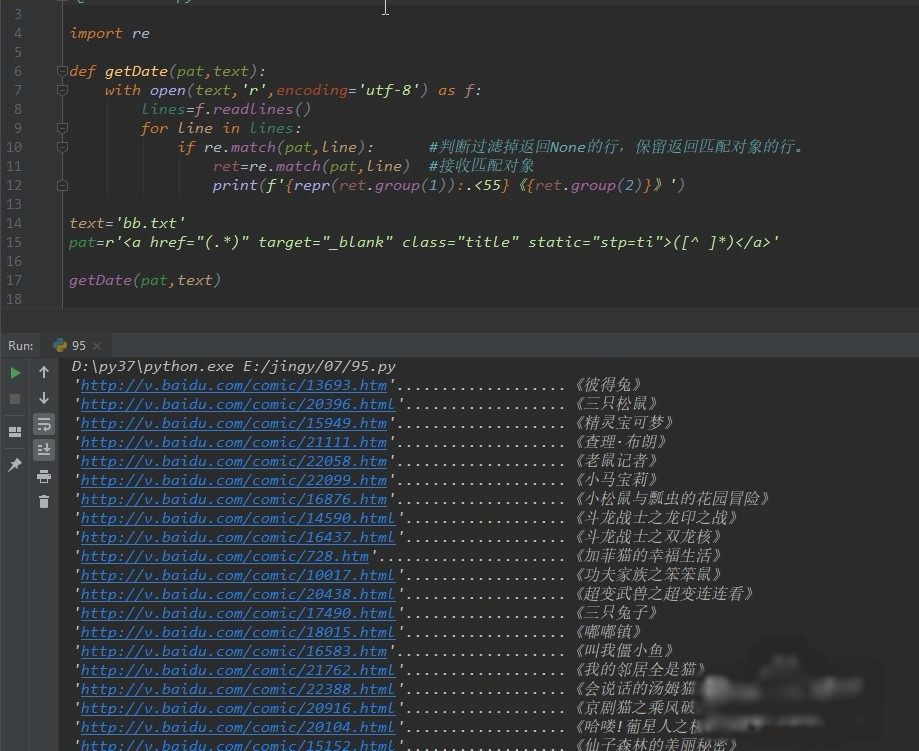
打开百度视频的动漫,复制源代码,存为bb.txt。
同样可以爬取网址和视频名称。
以上仅是练习match()函数的例子。
以上就是关于python如何用match()函数爬数据的全部内容,感谢大家的阅读和对脚本之家的支持。
版权声明:
本站所有资源均为站长或网友整理自互联网或站长购买自互联网,站长无法分辨资源版权出自何处,所以不承担任何版权以及其他问题带来的法律责任,如有侵权或者其他问题请联系站长删除!站长QQ754403226 谢谢。






