
本文来源吾爱破解论坛
本帖最后由 liangyun 于 2019-3-1 15:24 编辑
python爬取免费优质IP归属地查询接口
说明;对过程不感兴趣的朋友可以直接看倒数第二段代码,在最后的位置
另外,最近很多人说学python热,但是用途并不大,甚至不好找工作,新手入坑还望慎重.另外,我是做java的,python是业余爱好,我不会为我说的话承担后果
还有就是,好多人整天爬虫真的没意思,因为,暂时还没有实现价值.或许可以搞一些有价值的东西爬一下,以学习为目的的话,后果并不严重(不要以装B为目的)
具体不表,我今天要做的工作就是: 需要将数据库中大量ip查询出起归属地
刚开始感觉好简单啊,毕竟只需要从百度找个免费接口然后来个python脚本跑一晚上就ok了嘛~但是,网上免费接口要么限制访问频率(淘宝的),要么限制访问次数(百度及其他)
没辙了,从百度找到了几个在线查询的接口,要么不够准确(或者说她们的数据库太旧了),要么就是速度太慢了,跟限制访问似的(没办法,小规模人家的服务器的确不够好)
于是乎就想到了百度首页的ip接口,就这货:
为了防止泄露隐私,其中ip地址信息已经在控制台稍作修改
随便输入一个ip,点击查询
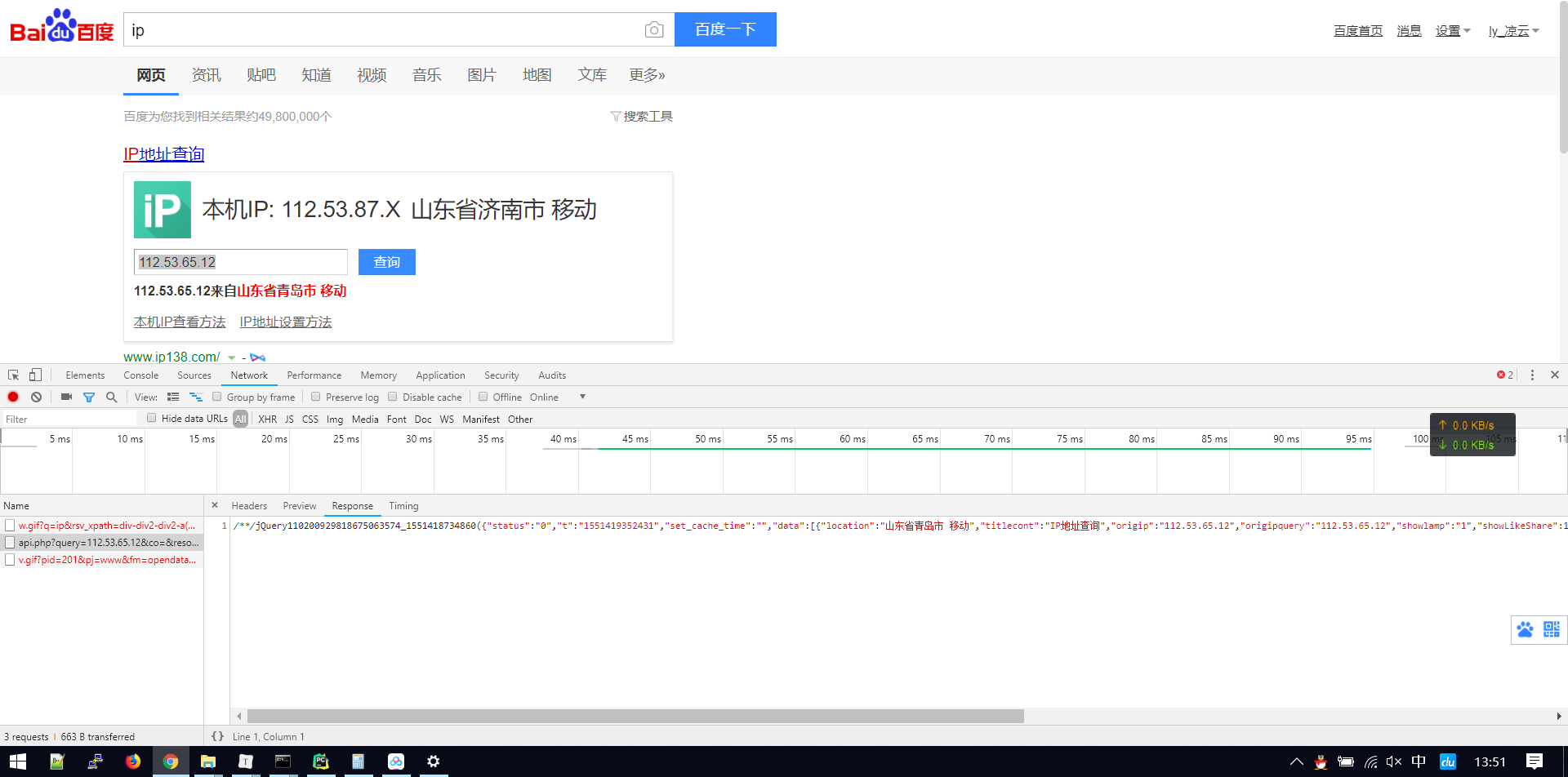
没想到,百度的接口竟然就这么暴露出来了,如此简单,试试能不能直接用
ip00.pyfrom pprint import pprint
import requests
res = requests.get(
'https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?query=112.53.65.12&co=&resource_id=6006&t=1551419352431&ie=utf8&oe=gbk&cb=op_aladdin_callback&format=json&tn=baidu&cb=jQuery110200929818675063574_1551418734860&_=1551418734868')
pprint(res.text)返回结果:
('/**/jQuery110200929818675063574_1551418734860({"status":"0","t":"1551419352431","set_cache_time":"","data":[{"location":"山东省青岛市 '
'移动","titlecont":"IP地址查询","origip":"112.53.65.12","origipquery":"112.53.65.12","showlamp":"1","showLikeShare":1,"shareImage":1,"ExtendedLocation":"","OriginQuery":"112.53.65.12","tplt":"ip","resourceid":"6006","fetchkey":"112.53.65.12","appinfo":"","role_id":0,"disp_type":0}]});')
与浏览器访问返回结果一样,这个太出乎意料了,好吧,b厂还是留了点情面的,可是他们家的接口只能按年来买,大概要999RMB/年
再测试一下换个 ip 地址继续查询还能不能查到结果(防止后面的数据是加密的)
ip01.py这个呢,其实最好的办法是在浏览器中进行测试,换个ip看一下控制台的url会不会有变化(主要是后面的参数),可能会存在加密数据,其实这个我测试了,会有一个参数变化 ,但是我重复提交时没发生改变一样能够请求数据,几乎就可以说明这个参数是迷惑用的(也可能是时间戳吧,我忘了具体什么参数了.时间戳的话就更好了,为了防止浏览器有缓存的)
from pprint import pprint
import requests
res = requests.get(
'https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?query=112.53.54.12&co=&resource_id=6006&t=1551419352431&ie=utf8&oe=gbk&cb=op_aladdin_callback&format=json&tn=baidu&cb=jQuery110200929818675063574_1551418734860&_=1551418734868')
pprint(res.text)返回结果:
('/**/jQuery110200929818675063574_1551418734860({"status":"0","t":"1551419352431","set_cache_time":"","data":[{"location":"广东省 '
'移动","titlecont":"IP地址查询","origip":"112.53.54.12","origipquery":"112.53.54.12","showlamp":"1","showLikeShare":1,"shareImage":1,"ExtendedLocation":"","OriginQuery":"112.53.54.12","tplt":"ip","resourceid":"6006","fetchkey":"112.53.54.12","appinfo":"","role_id":0,"disp_type":0}]});')
ok,数据更换ip也是没有问题的,也不需要伪装agent
那么我们来尝试一下访问频率有没有限制:
这里先为大家介绍一个库:faker
faker_test.py这是一个python造假用的库,可以生成很多测试数据,姓名地址电话等等信息
这里推荐一位陌生老哥的博客:https://www.cnblogs.com/blueteer/p/10277725.html,如果不知道这个库,可以看一眼下面的 小demo:
from faker import Faker
f = Faker('zh-CN')
print(f.ipv4())返回结果:
101.208.5.200ip02.py这段代码就这点功能,就是可以生成随机ip地址
from pprint import pprint
import requests
from faker import Faker
f = Faker('zh-CN')
for i in range(100):
ip = f.ipv4()
res = requests.get(
'https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?query=' + ip +
'&co=&resource_id=6006&t'
'=1551419352431&ie=utf8&oe=gbk&cb=op_aladdin_callback&format=json&tn=baidu&cb'
'=jQuery110200929818675063574_1551418734860&_=1551418734868')
pprint(res.text)这里稍微整理了一下url,就是换了个行而已
返回结果(太多了 ,截个图意思意思)

速度挺快,待会儿再测试一下它的耗时到底有多少
数据杂乱不好整理,直接来个简单粗暴的分割字符串吧:
稍作修改后:
ip03.pyimport requests
from faker import Faker
f = Faker('zh-CN')
for i in range(100):
ip = f.ipv4()
res = requests.get(
'https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?query=' + ip +
'&co=&resource_id=6006&t'
'=1551419352431&ie=utf8&oe=gbk&cb=op_aladdin_callback&format=json&tn=baidu&cb'
'=jQuery110200929818675063574_1551418734860&_=1551418734868')
text = res.text
location = text.split('location":"')[1].split('","titlecont')[0]
print(location)
吓死我了,刚才断网了,我还以为百度的这条路只能走这么远了呢,毕竟我上午已经弄了不少数据了,下午就不行的话,我这一上午岂不是白瞎了
返回结果
澳大利亚
澳大利亚
广东省 电信
韩国
美国
美国
美国
比利时
美国
美国
...后面的不发了,太长了最后,来计个时
ip04.pyfrom time import time
import requests
from faker import Faker
# 获取当前秒级时间戳
t1 = int(time())
f = Faker('zh-CN')
for i in range(100):
ip = f.ipv4()
res = requests.get(
'https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?query=' + ip +
'&co=&resource_id=6006&t'
'=1551419352431&ie=utf8&oe=gbk&cb=op_aladdin_callback&format=json&tn=baidu&cb'
'=jQuery110200929818675063574_1551418734860&_=1551418734868')
text = res.text
location = text.split('location":"')[1].split('","titlecont')[0]
print(location)
t2 = int(time())
print(t2 - t1)返回结果:
...
美国
美国
美国
荷兰
美国
美国
澳大利亚
澳大利亚
19还不错吧,100个耗时19秒,想要更快可以试试java或者多线程吧,反证我就用这一次,而且也不赶时间,估计今晚就把我那些数据搞定了
最后娱乐一下,缩减一下代码行数(计时就去掉了,反正对我也没什么实际用途)
import requests;from faker import Faker;f = Faker('zh-CN');print([requests.get('https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?query=' + f.ipv4() +'&resource_id=6006&_='+str(i)).text.split('ation":"')[1].split('","tit')[0] for i in range(10)])python一行代码(251字)搞定爬取百度ip接口并实现查询数据(欢呼)这里主要是精简了一部分url,不知道修改后还好不好使了
好险这字数,还好没再删东西,哈哈哈,别整这些没用的了
版权声明:
本站所有资源均为站长或网友整理自互联网或站长购买自互联网,站长无法分辨资源版权出自何处,所以不承担任何版权以及其他问题带来的法律责任,如有侵权或者其他问题请联系站长删除!站长QQ754403226 谢谢。







