
本文来源吾爱破解论坛
python scrapy爬取电影天堂所有电影 hello,下午好,这次给大家带来的是电影天堂的爬虫,希望大家会喜欢,项目采用的scrapy框架进行爬取,没有用到数据库,直接存成csv格式,这次也没有加入分布式,逻辑比较简单,主要难点就是详情页的数据解析 主要用到的技术 scrapy xpath 和re的结合使用 正则表达式的使用
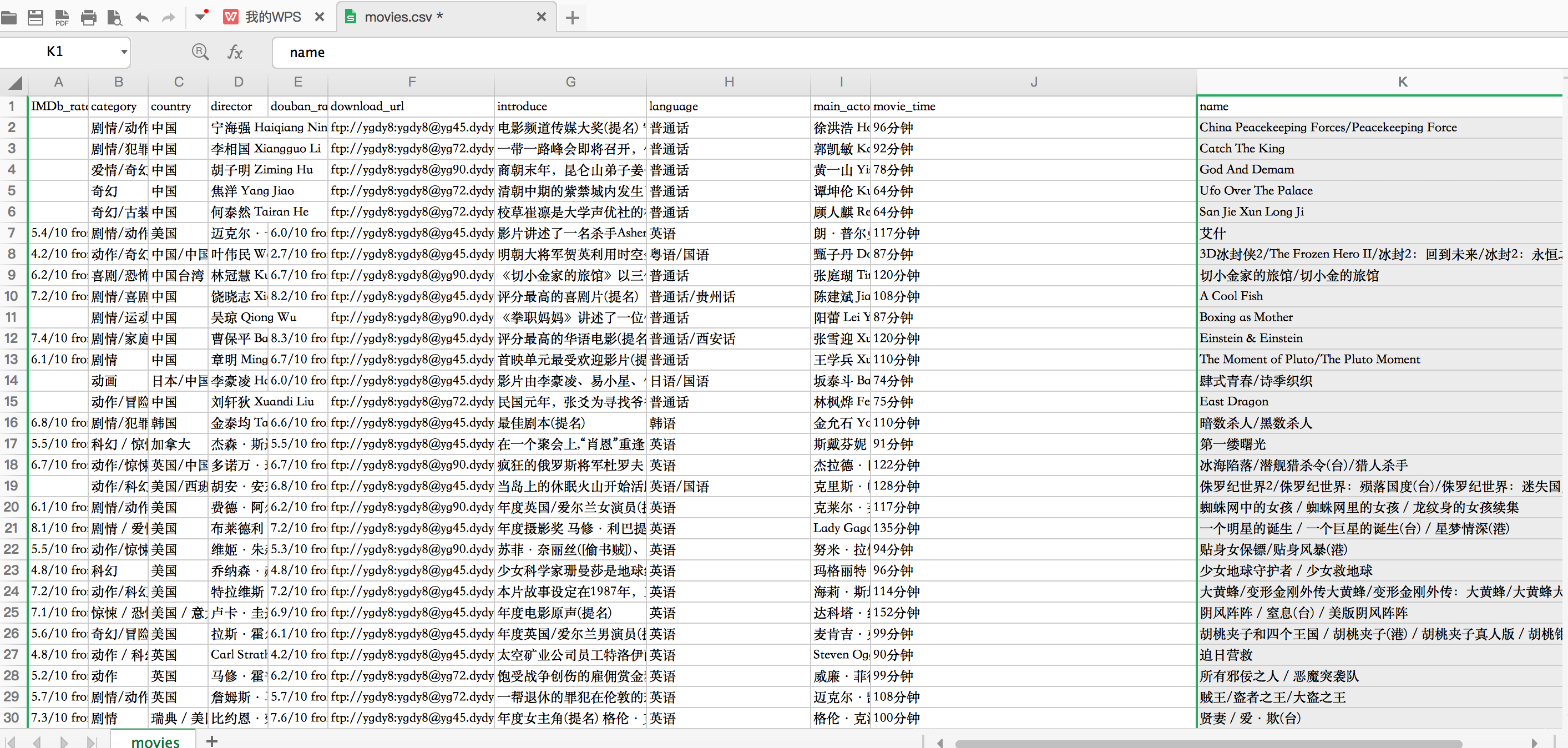
项目截图
核心源码 :beers:
# -*- coding: utf-8 -*-
import scrapy
from dytt8.items import Dytt8Item
class Dytt8SpiderSpider(scrapy.Spider):
name = 'dytt8_spider'
allowed_domains = ['www.dytt8.net']
start_urls = ['http://www.dytt8.net/']
headers = {
'connection': "keep-alive",
'pragma': "no-cache",
'cache-control': "no-cache",
'upgrade-insecure-requests': "1",
'user-agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10\_13\_4) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/71.0.3578.98 Safari/537.36",
'dnt': "1",
'accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
'accept-encoding': "gzip, deflate, br",
'accept-language': "zh-CN,zh;q=0.9,en;q=0.8",
'cookie': "XLA_CI=97928deaf2eec58555c78b1518df772a",
}
def start_requests(self):
base_url = 'https://www.dytt8.net/html/gndy/{}/index.html'
categories = ['china', 'rihan', 'oumei', 'dyzz']
for category in categories:
yield scrapy.Request(base_url.format(category), headers=self.headers, callback=self.parse)
def parse(self, response):
# xpath('//div[contains(@class,"a") and contains(@class,"b")]') #它会取class含有有a和b的元素
detail_urls = response.xpath('//a[@class="ulink"]/@href').extract()
detail_urls = [url for url in detail_urls if 'index' not in url]
print(detail_urls)
for url in detail_urls:
yield scrapy.Request(response.urljoin(url), headers=self.headers, callback=self.detail)
def detail(self, response):
item = Dytt8Item()
name = response.xpath('//p/text()').re('◎译\\u3000\\u3000名\\u3000(.*)')
category = response.xpath('//p/text()').re('◎类\\u3000\\u3000别\\u3000(.*)')
country = response.xpath('//p/text()').re('◎产\\u3000\\u3000地\\u3000(.*)')
douban_rate = response.xpath('//p/text()').re('◎豆瓣评分\\u3000(.*)')
language = response.xpath('//p/text()').re('◎语\\u3000\\u3000言\\u3000(.*)')
publish_date = response.xpath('//p/text()').re('◎上映日期\\u3000(.*)')
IMDb_rate = response.xpath('//p/text()').re('◎IMDb评分\\u3000(.*)')
movie_time = response.xpath('//p/text()').re('◎片\\u3000\\u3000长\\u3000(.*)')
director = response.xpath('//p/text()').re('◎导\\u3000\\u3000演\\u3000(.*)')
main_actor = response.xpath('//p/text()').re('◎主\\u3000\\u3000演\\u3000(.*)')
introduce = response.xpath('//p/text()').re('\\u3000\\u3000(.*)')
download_url = response.xpath('//a/text()').re('ftp.*')
if name:
item['name'] = name[0]
if category:
item['category'] = category[0]
if country:
item['country'] = country[0]
if douban_rate:
item['douban_rate'] = douban_rate[0]
if language:
item['language'] = language[0]
if publish_date:
item['publish_date'] = publish_date[0]
if IMDb_rate:
item['IMDb_rate'] = IMDb_rate[0]
if movie_time:
item['movie_time'] = movie_time[0]
if director:
item['director'] = director[0]
if main_actor:
item['main_actor'] = main_actor[0]
if download_url:
item['download_url'] = ''.join(download_url)
if introduce:
item['introduce'] = introduce[-1]
yield item如何使用
pip install scrapy
git clone https://github.com/guapier/dytt8.git
cd dytt8
python3 main.py
版权声明:
本站所有资源均为站长或网友整理自互联网或站长购买自互联网,站长无法分辨资源版权出自何处,所以不承担任何版权以及其他问题带来的法律责任,如有侵权或者其他问题请联系站长删除!站长QQ754403226 谢谢。
- 上一篇: 爬取5K分辨率超清唯美壁纸
- 下一篇: 爬虫之酷狗音乐TOP500歌曲信息






