
这篇文章主要介绍了python pandas cumsum求累计次数的用法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
本文主要是针对 cumsum函数的一些用法。具体应用场景看下面的数据集。
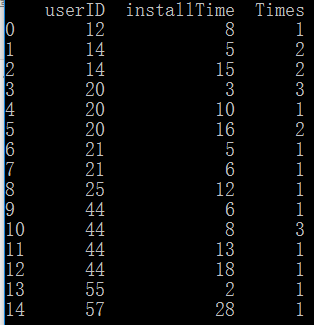
第一列是userID,第二列是安装的时间,第三列是安装的次数。
我们现在想做一件事情。就是统计用户在某一天前累计的安装次数。
譬如,对userID为20的用户,问在16天前,其安装次数为多少? 答案应该是4次。用python的实现也很简单。
又譬如,userID为44在19天前安装的次数,那就应该是1+3+1+1=6次。
具体代码:(假设数据集为data)
由于是针对每个userID,所以是需要将userID划分一下(这个方法在组内排序的时候有提到,可以参考前面的文章)。
所以才有下面这一句
groupby(['userID'])
然后,分完组后需要统计的Times,所以就是下面这一句
data['Times'].groupby(['userID'])
最后,我们需要的是累加量,所以,用cumsum()这个函数。
data['sum_Times']=data['Times'].groupby(['userID']).cumsum()
用得到的结果放在一列。
最后得到结果如下:
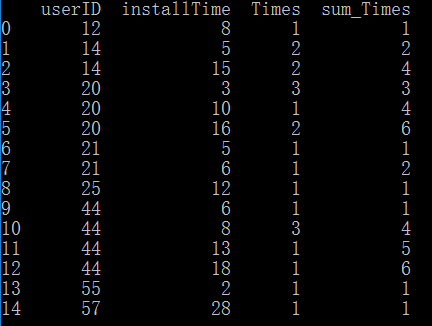
可以从sum_Times这列看到,每一个值都是相应userID在前一行的累加值。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
版权声明:
本站所有资源均为站长或网友整理自互联网或站长购买自互联网,站长无法分辨资源版权出自何处,所以不承担任何版权以及其他问题带来的法律责任,如有侵权或者其他问题请联系站长删除!站长QQ754403226 谢谢。
- 上一篇: Django框架视图层URL映射与反向解析实例分析
- 下一篇: PyCharm中代码字体大小调整方法






