
筛选和排序是Excel中使用频率最多的功能,通过这个功能可以很方便的对数据表中的数据使用指定的条件进行筛选和计算,以获得需要的结果。在Pandas中通过.sort和.loc函数也可以实现这两 个功能。.sort函数可以实现对数据表的排序操作,.loc函数可以实现对数据表的筛选操作。本篇文章将介绍如果通过Pandas的这两个函数完成Excel中的筛选和排序操作。
首选导入需要使用的Pandas库和numpy库,读取并创建数据表,将数据表命名为lc。
import pandas as pd
import numpy as np
lc=pd.DataFrame(pd.read_csv('LoanStats3a.csv',header=1))
创建数据表后,开始使用Pandas的.sort函数对数据表进行排序操作,下面是Pandas官方对.sort函数语法和使用方法的说明。.sort函数主要包含6个参数,columns为要进行排序的列名称, ascending为排序的方式true为升序,False为降序,默认为true。axis为排序的轴,0表示index,1表示columns,当对数据列进行排序时,axis必须设置为0。inplace默认为False,表示对数据 表进行排序,不创建新实例。Kind可选择排序的方式,如快速排序等。na_position对NaN值的处理方式,可以选择first和last两种方式,默认为last,也就是将NaN值放在排序的结尾。

在了解了.sort函数的语法和使用方法后,我们开始使用这个函数对数据进行排序操作,数据源来自Lending Club 2017-2011年的公开数据。首先对单列数据进行排序。
对单列数据进行排序
升序
单列数据的排序的方法很简单,按照.sort函数中的介绍,写清楚要排序的数据表名称,以及要进行排序的列名称即可。具体的代码和排序结果如下所示,其中lc是前面我们读取并创建的数据表名称,loan_amnt是要进行排序的列名称。这里我们对lc数据表按loan_amnt列进行升序排列。这里需要说明的是ascending参数的默认值是True,也就是升序。因此下面的两种写法效果是一样的 。
lc.sort(["loan_amnt"]) lc.sort(["loan_amnt"],ascending=True)
降序
将ascending参数的值改为False就完成对数据表的降序排列工作。与升序排列的数据表相比可以发现升序排列将loan_amnt列的最小值放在了前面,因此我们可以判断loan_amnt的最小金额为500,与之相反,降序排列将最大值放在了前面,因此loan_amnt的最大金额应该为35000。这里我们没有设置na_position参数的值,因此按默认情况loan_amnt列的NaN值在排序的结尾显示。以下显示了降序排列的代码和结果。
lc.sort(["loan_amnt"],ascending=False)
对多列数据进行排序
除了对单列数据进行排序以外,.sort函数还可以对多列数据进行排序操作。下面我们分别对loan_amnt和int_rate字段进行降序排列,以下是具体的代码和排序结果,与单列数据排序的代码相比,这里只增加了一个新的列名称int_rate。
lc.sort(["loan_amnt","int_rate"],ascending=False)
我们将需要排序的两个列名称互换位置,再次执行降序排列操作。观察两次的排序结果可以发现,这次的结果与之前的结果有一些差异。Loan_amnt字段的排序结果有些混乱,有些较小的值排在了较大值的前面。这是因为第一次排序时loan_amnt是第一排序字段,int_rate是第二排序字段。两个字段交换位置第二次排序后,int_rate变成了第一排序字段,loan_amnt变成了第二排序字段 。
lc.sort(["int_rate","loan_amnt"],ascending=False)

获取金额最小前10项
在完成了对数据表排序的操作后,我们可以对数据表进行简单的筛选,例如获取loan_amnt金额最小的前10名数据。具体的方法是先对lc数据表按loan_amnt升序排列,然后取前10名的数据。NaN值默认在排序结果的结尾显示。以下是具体代码和结果。与前面单列升序排列的代码相比只在结尾增加了.head()函数。
lc.sort(["loan_amnt"],ascending=True).head(10)
获取金额最大前10项
获取金额最大前10项的代码与获取金额最小前10项略有差异,本来我们只需要复制前面的代码,然后将.head()函数改为tail()函数即可,但由于NaN值在排序的尾部,因此,我们将lc数据表按loan_amnt按降序排列,并取排名前10的数据。当然这并不是唯一的方法,我们还可以通过放弃NaN值的排序或者将NaN值在排序前部显示来解决这个问题。以下是具体的代码和执行结果。
lc.sort(["loan_amnt"],ascending=False).head(10)

介绍完排序功能后再来看下筛选,在筛选功能上Pandas使用的是.loc函数。以下是Pandas官方对.loc函数的语法和使用方法的说明。

单列数据筛选并排序
我们使用.loc对lc数据表中grade列为B值的数据条目进行了筛选操作,具体的代码和筛选结果如下。在代码中lc.loc[]是.loc函数的语法,lc[“grade”] == “B”是具体的筛选条件。由于数据表较大,因此在最后使用了head()函数只显示前5行筛选结果。从筛选结果来看grade列的值都为B。
lc.loc[lc["grade"] == "B"].head()
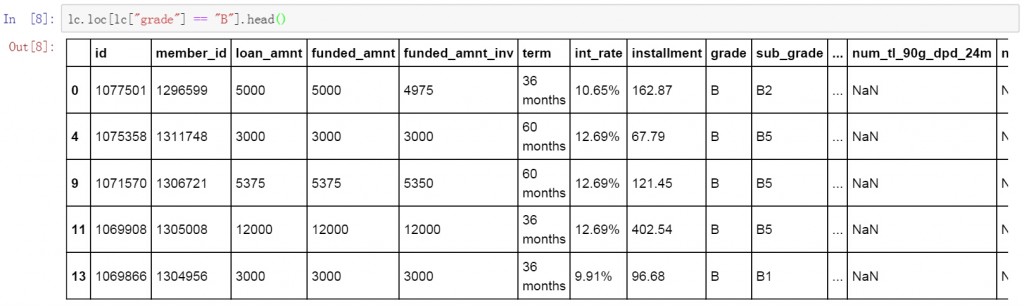
筛选条件除了”等于”(==)以外,还可以使用”不等于”(!=)来排除列中特定的值。我们使用”不等于”来筛选grade列中不是B值的数据条目。以下是具体的代码和筛选结果,可以看到筛选结果中的grade列里已经不包含B值了。
lc.loc[lc["grade"] != "B"].head()
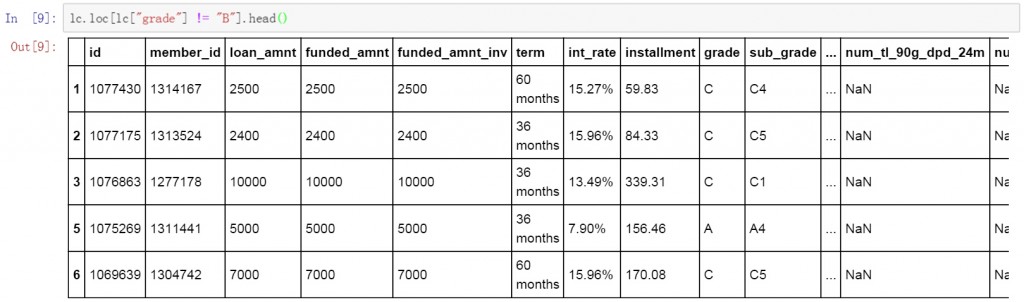
很多时候我们只关注数据表中某几列的数据,这时可以在前面筛选代码的基础上增加要显示的列名称和显示顺序。下面是具体的代码和筛选结果。代码部分与之前相比增加了要显示的列名称 [“member_id”, “loan_amnt”, “grade”]。其余部分均没有改变。在筛选结果的数据表中可以看到仅显示了我们在代码中列出的三列。
lc.loc[lc["grade"] == "B", ["member_id", "loan_amnt", "grade"]].head()
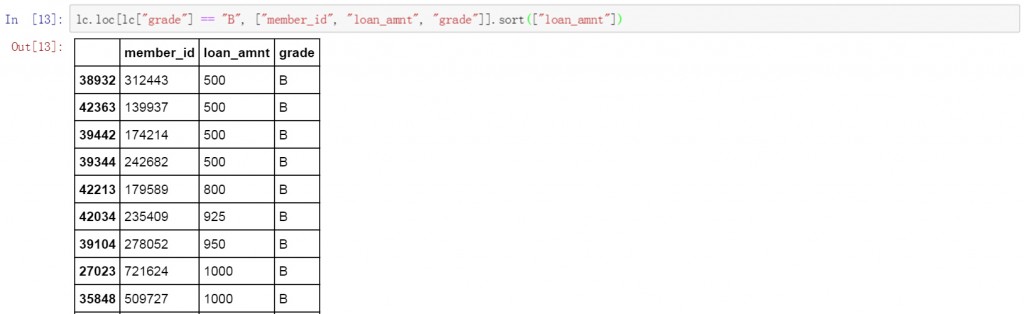
若要对筛选结果进行排序可以联合使用.loc函数和.sort函数。下面的代码中首先对数据表的grade列进行筛选,选择所有值为B的数据,并限定了结果中要显示的三列的名称。最后对筛选出的结果按loan_amnt的金额进行升序排序。
lc.loc[lc["grade"] == "B", ["member_id", "loan_amnt", "grade"]].sort(["loan_amnt"])
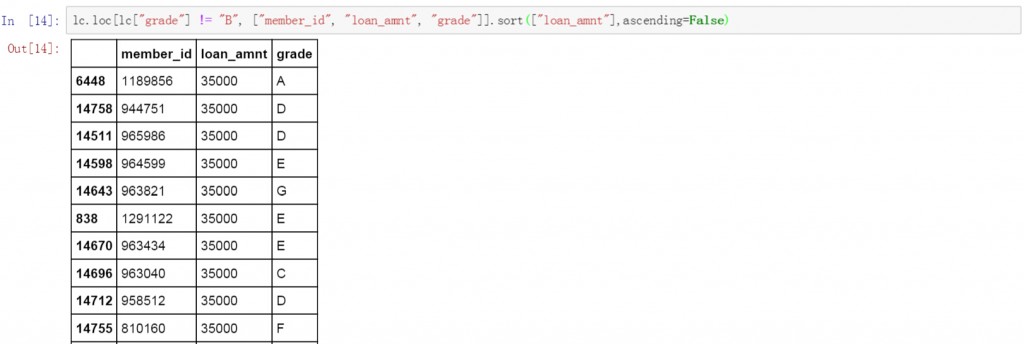
在代码后面增加ascending参数,并将值设置为False就可实现对筛选结果的降序排列。以下为具体的代码和筛选及排序结果。
lc.loc[lc["grade"] != "B", ["member_id", "loan_amnt", "grade"]].sort(["loan_amnt"],ascending=False)
多列数据筛选并排序
Pandas的.loc参数还可以同时对多列数据进行筛选,并且支持不同筛选条件逻辑组合。常用的筛选条件包括”等于”(==)”,不等于”(!),”大于”(>)”,小于”(<)”,大于等于”(>=)” ,小于等于”(<=)等等。逻辑组合包括”与”()和”或”()。下面我们将通过3条多列数据筛选代码逐一进行介绍。
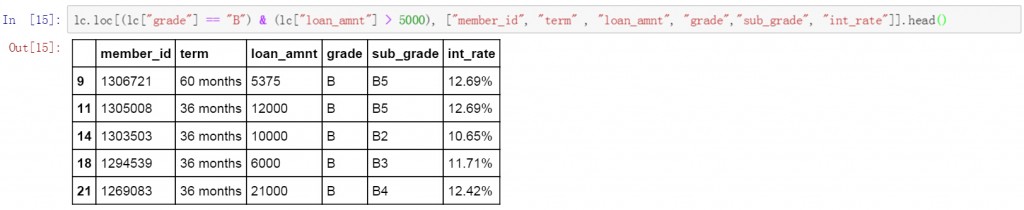
第一条代码使用”与”逻辑,筛选出了grade等于B,并且loan_amnt金额大于5000的数据。并限定了显示的列名称。从筛选结果中可以看出grade列的值都是B,loan_amnt的金额均大于5000。
lc.loc[(lc["grade"] == "B") & (lc["loan_amnt"]>5000), ["member_id", "term" , "loan_amnt", "grade","sub_grade", "int_rate"]].head()
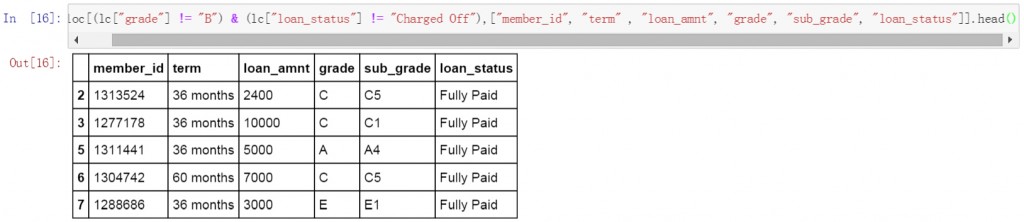
第二条代码也使用”与”逻辑,筛选出了grade不等于B,并且loan_status不等于Charged Off的数据,同时也限定了显示的列名称。从筛选结果中看grade列不包含B值,并且loan_status列不包含Charged Off值。
lc.loc[(lc["grade"] != "B") & (lc["loan_status"] != "Charged Off"),["member_id", "term" , "loan_amnt", "grade", "sub_grade", "loan_status"]].head()
第三条代码使用了”或”逻辑,筛选出了grade列值为B,或loan_amnt列金额大于5000的数据,同时也限定了显示的列名称。从筛选结果来看,grade列除了B值以外还保留了其他的值,而这些值在loan_amnt列的金额均大于5000。换句话说,一条数据只要grade列或loan_amnt列任意之一符合筛选条件,这条数据就会被显示。
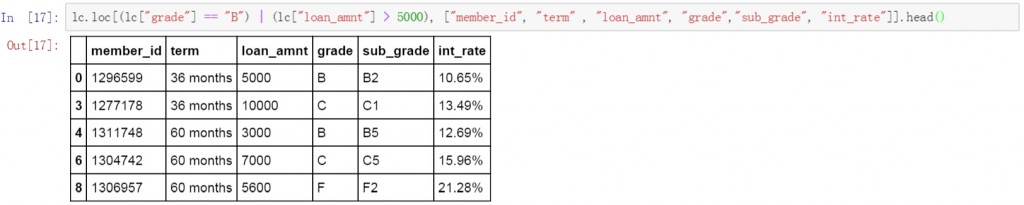
lc.loc[(lc["grade"] == "B") | (lc["loan_amnt"] > 5000), ["member_id", "term" , "loan_amnt", "grade","sub_grade", "int_rate"]].head()
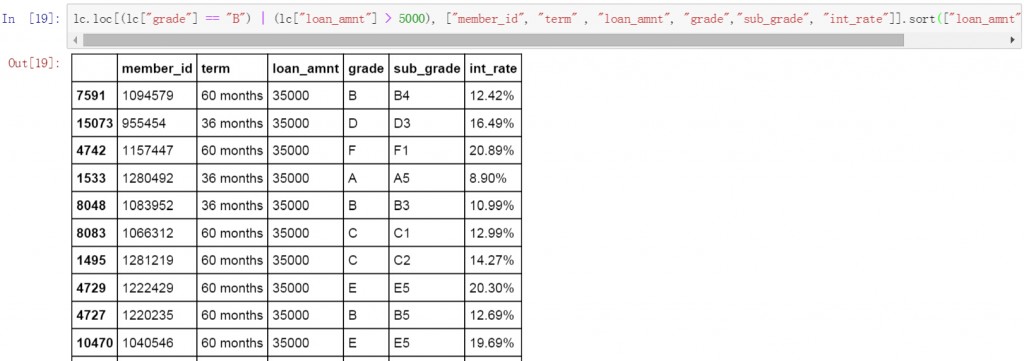
多列筛选也可以进行排序,方法与单列筛选后排序基本一样,下面的代码对多列筛选后的结果按loan_amnt列进行升序排序。由于筛选条件中限定了loan_amnt列的值要大于5000,因此排序的结果从5020开始。
lc.loc[(lc["grade"] == "B") & (lc["loan_amnt"] > 5000), ["member_id", "term" , "loan_amnt", "grade","sub_grade", "int_rate"]].sort(["loan_amnt"])
对多列筛选结果进行降序排序只需在前面升序排序代码的基础上增加ascending参数,并将值设定为False即可。下面是多列筛选后降序排序的代码和结果。
lc.loc[(lc["grade"] == "B") & (lc["loan_amnt"] > 5000), ["member_id", "term" , "loan_amnt", "grade","sub_grade", "int_rate"]].sort(["loan_amnt"],ascending=False)

无论是”与”条件,还是”或”条件都可以在筛选后使用排序。下面代码是对使用了“或”逻辑条件的筛选结果进行降序排序的代码和结果。
lc.loc[(lc["grade"] == "B") | (lc["loan_amnt"] > 5000), ["member_id", "term" , "loan_amnt", "grade","sub_grade", "int_rate"]].sort(["loan_amnt"],ascending=False)
Pandas中的排序和筛选基本介绍完了,在实际的分析工作中,筛选只是分析过程中的一个步骤,很多时候我们还需要对筛选后的结果进行汇总,例如求和,计数,或计算均值等等。也就是Excel中常用的sumifs和countifs函数。
按筛选条件求和(sumif, sumifs)
在单列筛选的代码后增加求和条件就相当于Excel中的sumif函数的功能。下面的代码在单列筛选的代码后增加了.loan_amnt.sum()的求和字段,表示对数据表中所有grade列值为B的loan_amnt金额求和。
lc.loc[lc["grade"] == "B",].loan_amnt.sum()

除了包含条件外,也可以对排除某一条件的数据求和。下面的代码与之前的正好相反,对数据表中所有grade列值不为B的loan_amnt金额求和。
lc.loc[lc["grade"] != "B",].loan_amnt.sum()

增加一个筛选条件就变成了Excel中的sumifs函数的功能。下面的代码中分别使用了两个条件对数据表进行筛选,并对最后的loan_amnt金额进行求和。
lc.loc[(lc["grade"] == "B") & (lc["loan_amnt"] > 5000)].loan_amnt.sum()

按筛选条件计数(countif, countifs)
将前面的.sum()函数换为.count()函数就变成了Excel中的countif函数的功能,下面的代码对数据表中grade列值为B的loan_amnt笔数进行计数。
lc.loc[lc["grade"] == "B"].loan_amnt.count()

与前面代码相反,下面的代码对数据表中grade列值不为B的所有loan_amnt笔数进行计数。
lc.loc[lc["grade"] != "B"].loan_amnt.count()

增加筛选条件,变成了Excel中的countifs函数的功能,下面的代码对数据表中grade列值为B,并且loan_amnt金额额大于5000的loan_amnt笔数进行计数。
lc.loc[(lc["grade"] == "B") & (lc["loan_amnt"] > 5000)].loan_amnt.count()

按筛选条件计算均值(averageif, averageifs)
有了sumifs和countifs,当然也少不了averageifs,在Pandas中.mean()是用来计算均值的函数,将.sum()和.count()替换为.mean()。就是pandas版的averageif和averageifs。下面的代码中计算了数据表中grade列值为B的loan_amnt金额均值。相当于Excel中的averageif函数的功能。
lc.loc[lc["grade"] == "B"].loan_amnt.mean()

与前面的代码证号相反,下面的代码计算了数据表中所有grade列值不为B的loan_amnt金额均值。
lc.loc[lc["grade"] != "B"].loan_amnt.mean()

增加一个筛选条件变成了Excel中的averageifs,不过这里好像又有一些不同,Excel中的sumifs,countifs和averageifs的计算逻辑是满足满足所有指定条件时,才对这些单元格进行求和或计数。而在下面的代码中我们使用了或条件,就是说只要满足两个条件中的任意一个都会进行计算。
lc.loc[(lc["grade"] == "B") | (lc["loan_amnt"] > 5000)].loan_amnt.mean()

按筛选条件获取最大值和最小值
最后两个是Excel中没有的函数功能,就是对筛选后的数据表计算最大值和最小值。方法很简单,将之前的sum()和count()换成max()和min()函数即可。下面是具体的代码和结果。
这条代码是计算数据表中grade列值为B的loan_amnt最大金额。
lc.loc[lc["grade"] == "B"].loan_amnt.max()

这条代码是计算数据表中grade列值不为B的loan_amnt最小金额。
lc.loc[lc["grade"] != "B"].loan_amnt.min()

以上这些也同样支持多条筛选后的计算,在此就不逐一列出了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
版权声明:
本站所有资源均为站长或网友整理自互联网或站长购买自互联网,站长无法分辨资源版权出自何处,所以不承担任何版权以及其他问题带来的法律责任,如有侵权或者其他问题请联系站长删除!站长QQ754403226 谢谢。







