
这篇文章主要介绍了详解pandas python 分组统计的方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
首先,看看本文所面向的应用场景:我们有一个数据集df,现在想统计数据中某一列每个元素的出现次数。这个在我们前面文章《如何画直方图》中已经介绍了方法,利用value_counts()就可以实现(具体回看文章)
但是,现在,我们考虑另外一个场景,我们假如要想统计其中两列元素出现次数呢?举个栗子:
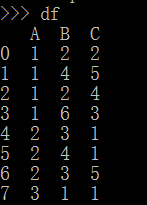
在df数据集中,如果我们想统计A、B两列的元素的出现情况,也就是说,得到如下表。
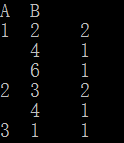
从上面的最后一列可以看到,在A、B两列中,1 2 出现了2次,1 4 出现1次 ,1 6出现1次,2 3出现了2次, 2 4 出现1次, 3 1出现了1次
具体实现的代码:
import pandas as pd df=pd.DataFrame([[1,2,2],[1,4,5],[1,2,4],[1,6,3],[2,3,1],[2,4,1],[2,3,5],[3,1,1]],columns=['A','B','C'])
gp=df.groupby(by=['A','B']) gp.size()
所以,如果想统计更多列,只要在groupby()中的by参数添加就可以,例如统计3列。
gp=df.groupby(by=['A','B','C'])
由gp.size()得到的是可以mulitiindex Series。
下面,要转化成DataFrame的结构。
newdf=gp.size() newdf.reset_index(name='times')
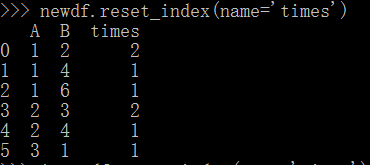
其中name中参数就是我们可以为最后一列添加新的名字,例如这里的“times”
这个时候newdf已经是DataFrame的类型了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
版权声明:
本站所有资源均为站长或网友整理自互联网或站长购买自互联网,站长无法分辨资源版权出自何处,所以不承担任何版权以及其他问题带来的法律责任,如有侵权或者其他问题请联系站长删除!站长QQ754403226 谢谢。







