
本次博客分享的内容为基于有道在线翻译实现一个实时翻译小程序,本次任务是参考小甲鱼的书《零基础入门学习Python》完成的,书中代码对于当前的有道词典并不适用,使用后无法实现翻译功能,在网上进行学习之后解决了这一问题。
2、前置工作
1)由于有道在线翻译是“反爬虫”的,所以在编写该程序的时候需要使用到User-Agent,通过使用request模块中的headers参数,对它进行适当的设置就可以将程序访问伪装为浏览器访问,有两种方法可以添加headers参数,我使用的方法是通过add_header()方法往Request对象中添加headers参数;
2)我使用的是360浏览器,获取它User-Agent的方法是在地址栏中输入about:version即可,结果如下图:

3)在获得该参数后还需要获取有道翻译的data数据,首先先打开有道翻译界面,然后打开其审查元素,点击netwoek,然后在翻译框内输入word点击翻译,找到如下图所示的位置:
4)一直往下滑动,就可以找到data参数,在编程时的设置就需要按照这里来完成,如下图:
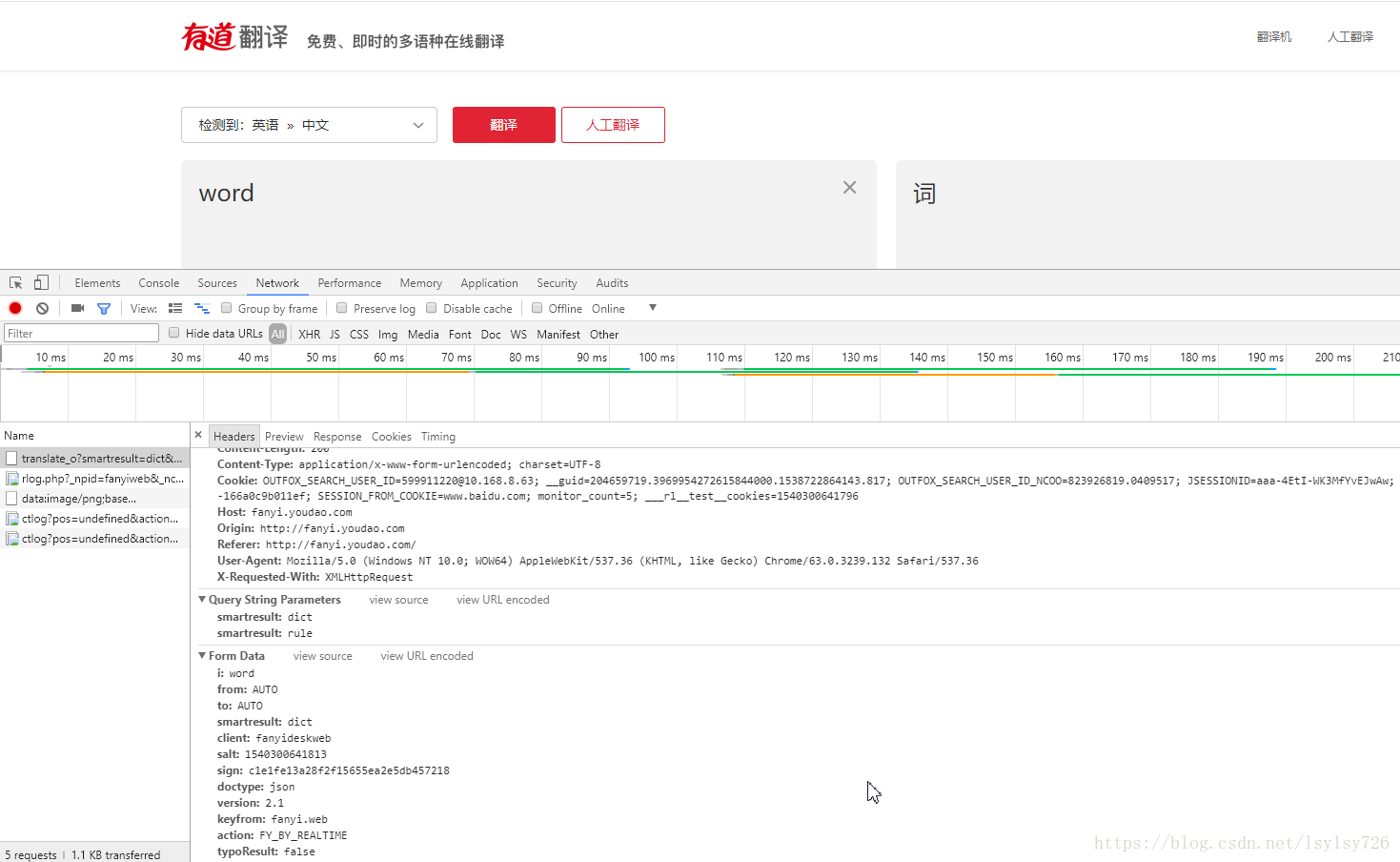
其中在headers中需要设置的Referer及User-Agent也在上图中可以找到。
3、任务代码
在程序的编写中需要使用到许多python模块,包括urllib、json 、time等等。
对于urllib在上一篇博客中已经用到了,它的作用是一个高级的 web 交流库,其核心功能就是模仿web浏览器等客户端,去请求相应的资源,并返回一个类文件对象。
json是一种轻量级的数据交换格式,易于人阅读和编写,我们需要使用json.loads 解码 json数据。
time是用于获取当前时间戳并延迟提交数据,延迟提交数据虽然会降低工作效率,但是也降低了ip被网页拉黑的风险。
具体的代码如下图所示:
import urllib.request #导入urllib.request库 import urllib.parse #导入urllib.parse库 import json #导入json库 import time #导入time库 import random #导入random库 import hashlib #导入hashlib库 url = "http://fanyi.youdao.com/translate_o" />4、总结
书上的知识是否正确还需要自己敲一边代码才能进行验证,所以说动手才是最重要的,本次制作这个翻译小程序,由于书本知识的错误,我通过网上查找资料才解决了这个问题,从中也学到了许多知识,希望自己能继续加油,学到更多的知识。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
版权声明:
本站所有资源均为站长或网友整理自互联网或站长购买自互联网,站长无法分辨资源版权出自何处,所以不承担任何版权以及其他问题带来的法律责任,如有侵权或者其他问题请联系站长删除!站长QQ754403226 谢谢。






