
piaodoo 第6478页
-

分析并输出Python代码依赖的库的实现代码
这篇文章主要介绍了分析并输出Python代码依赖的库的实现代码,需要的朋友可以参考下 用法: 分析一个脚本的依赖: analysis_dependency.py script1.py 递归分析依赖: analysis_dependency.py script1.py -r #!/usr/bin/env python # encoding: utf-8 # source: https://github.com/MrLYC/y...
-

python根据京东商品url获取产品价格
闲着没事尝试抓一下京东的数据,需要使用到的库有:BeautifulSoup,urllib2,在Python2下测试通过 京东商品详细的请求处理,是先显示html,然后再ajax请求处理显示价格。 1.可以运行js,并解析之后得到的html 2.模拟js请求,得到价格 # -*- coding: utf-8 -*- """ 根据京东url地址,获取商品价格 京东请求处理过程,先显示html页面,然后通过ajax get请求...
-

python制作一个桌面便签软件
这篇文章主要介绍了python制作一个桌面便签软件分别给大家附上ubuntu和windows版的程序及源码,有需要的小伙伴可以参考下。 # 2014.10.15 更新了memo.zip, 网盘的exe:修复:1.隔日启动不能正常加载json,加入:1.隐藏任务栏图标,2.通过垃圾桶进行窗口移动。 # 2014.10.8 10.36更新了memo.zip # 2014.10.8 13.17 更新了memo.zip 在win10测...
-

Python 实现简单的电话本功能
这篇文章主要介绍了Python 实现简单的电话本功能的相关资料,包括添加联系人信息,查找姓名显示联系人,存储联系人到 TXT 文档等内容,十分的细致,有需要的小伙伴可以参考下 myPhoneBook2.py #!/usr/bin/python # -*- coding: utf-8 -*- import re class PhoneBook(object): '''这是一个电话簿脚本。 该脚本能够实现 Add...
-
python批量提取word内信息
这里给大家分享的是php读取word并提取word内信息的方法,十分的简单实用,有需要的小伙伴可以参考下。 单位收集了很多word格式的调查表,领导需要收集表单里的信息,我就把所有调查表放一个文件里,写了个python小程序把所需的信息打印出来 #coding:utf-8 import os import win32com from win32com.client import Dispatch, constant...
-

python实现下载指定网址所有图片的方法
这篇文章主要介绍了python实现下载指定网址所有图片的方法,涉及Python针对页面的读取、遍历及文件操作的相关技巧,具有一定参考借鉴价值,需要的朋友可以参考下 本文实例讲述了python实现下载指定网址所有图片的方法。分享给大家供大家参考。具体实现方法如下: #coding=utf-8 #download pictures of the url #useage: python downpicture.py www.ba...
-
Python实现多线程抓取妹子图
本文给大家汇总了3款由Python制作的多线程批量抓取美图的代码,主要是将获取图片链接任务和下载图片任务用线程分开来处理了,而且这次的爬虫不仅仅可以爬第一页的图片链接的,有类似需求的小伙伴可以参考下。 心血来潮写了个多线程抓妹子图,虽然代码还是有一些瑕疵,但是还是记录下来,分享给大家。 Pic_downloader.py # -*- coding: utf-8 -*- """ Created on Fri Aug 07 1...
-
通过Python来使用七牛云存储的方法详解
这篇文章主要介绍了通过Python来使用七牛云存储的方法详解,七牛云存储是国内领先的服务器数据备份解决方案商,需要的朋友可以参考下 本教程旨在介绍如何使用七牛的Python SDK来快速地进行文件上传,下载,处理,管理等工作。 安装 首先,要使用Python的SDK必须要先安装。七牛的Python SDK是开源的,托管在Github上面,项目地址为https://github.com/qiniu/python-sdk。 安装的...
-
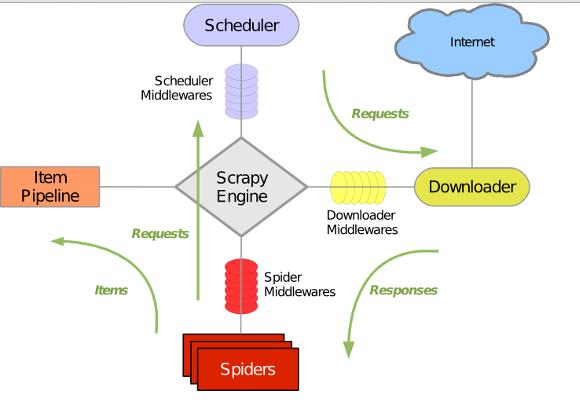
Python爬虫框架Scrapy实战之批量抓取招聘信息
网络爬虫又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者,是按照一定的规则,自动抓取万维网信息的程序或者脚本。这篇文章主要介绍Python爬虫框架Scrapy实战之批量抓取招聘信息,有需要的朋友可以参考下 网络爬虫抓取特定网站网页的html数据,但是一个网站有上千上万条数据,我们不可能知道网站网页的url地址,所以,要有个技巧去抓取网站的所有html页面。Scrapy是纯Python实现的爬虫框架,用户...
-

深入理解Python中命名空间的查找规则LEGB
这篇文章主要介绍了深入理解Python中命名空间的查找规则LEGB,作者根据Python3.x版本进行讲解,需要的朋友可以参考下 名字空间 Python 的名字空间是 Python 一个非常核心的内容。 其他语言中如 C 中,变量名是内存地址的别名,而在 Python 中,名字是一个字符串对象,它与他指向的对象构成一个{name:object}关联。 Python 由很多名字空间,而 LEGB 则是名字空间的一种查找规则。 作...