
python教程 第152页
-

Python字符串、元组、列表、字典互相转换的方法
这篇文章主要介绍了Python字符串、元组、列表、字典互相转换的方法的相关资料,需要的朋友可以参考下 废话不多说了,直接给大家贴代码了,代码写的不好还去各位大侠见谅。 #-*-coding:utf-8-*- #1、字典 dict = {'name': 'Zara', 'age': 7, 'class': 'First'} #字典转为字符串,返回:<type 'str'> {'age': 7, 'name':...
-
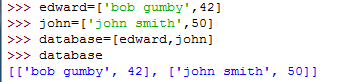
Python随手笔记第一篇(2)之初识列表和元组
Python中,列表和元组是一种数据结构:序列,序列中的每个元素都被分配一个序号,元素的位置,第一原元素的位置为0,因此类推,序列是最基本的数据结构,本文给大家分享Python随手笔记第一篇(2)之初识列表和元组,感兴趣的朋友一起学习吧 Python中,列表和元组是一种数据结构:序列,序列中的每个元素都被分配一个序号,元素的位置,第一原元素的位置为0,因此类推。序列是最基本的数据结构,列表和元组他们之间具有一定的区别,即列表可...
-
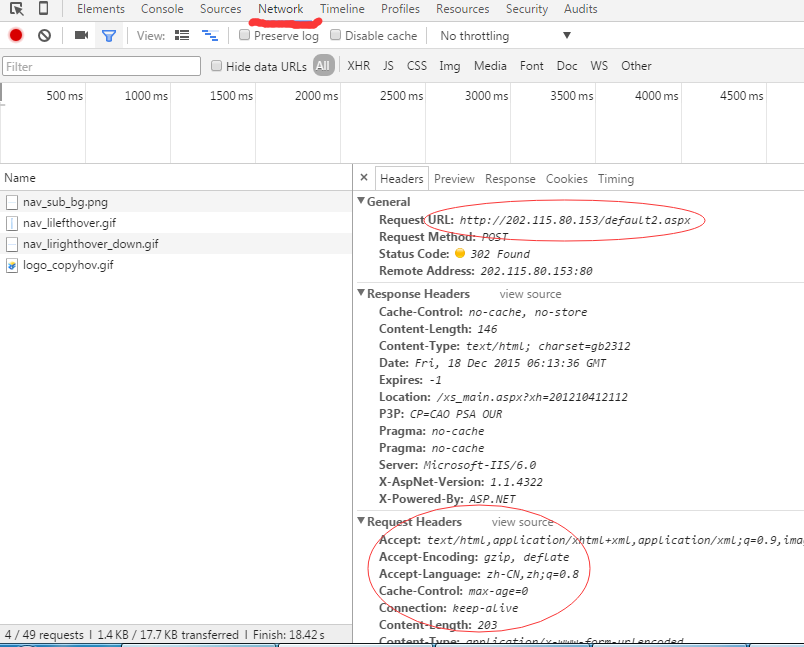
Python爬虫模拟登录带验证码网站
这篇文章主要介绍了Python爬虫模拟登录带验证码网站的相关资料,需要的朋友可以参考下 爬取网站时经常会遇到需要登录的问题,这是就需要用到模拟登录的相关方法。python提供了强大的url库,想做到这个并不难。这里以登录学校教务系统为例,做一个简单的例子。 首先得明白cookie的作用,cookie是某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据。因此我们需要用Cookielib模块来保持网站的c...
-
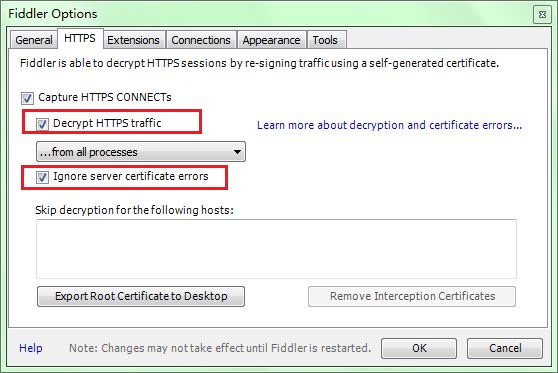
Fiddler如何抓取手机APP数据包
Fiddler,这个是所有软件开发者必备神器!这款工具不仅可以抓取PC上开发web时候的数据包,而且可以抓取移动端,通过本文给大家介绍Fiddler如何抓取手机APP数据包,感兴趣的朋友一起学习吧 Fiddler,这个是所有软件开发者必备神器!这款工具不仅可以抓取PC上开发web时候的数据包,而且可以抓取移动端(Android,Iphone,WindowPhone等都可以)。 第一步:下载神器Fiddler,下载链接: ht...
-

Python爬虫抓取手机APP的传输数据
大多数APP里面返回的是json格式数据,或者一堆加密过的数据 。这里以超级课程表APP为例,抓取超级课程表里用户发的话题 大多数APP里面返回的是json格式数据,或者一堆加密过的数据 。这里以超级课程表APP为例,抓取超级课程表里用户发的话题。 1、抓取APP数据包 方法详细可以参考这篇博文:Fiddler如何抓取手机APP数据包 得到超级课程表登录的地址:http://120.55.151.61/V2/StudentSk...
-

Python 列表排序方法reverse、sort、sorted详解
本文给大家介绍的是Python中列表排序方法中的reverse、sort、sorted操作方法,以及他们直接的区别介绍,有需要的小伙伴可以参考下。 python语言中的列表排序方法有三个:reverse反转/倒序排序、sort正序排序、sorted可以获取排序后的列表。在更高级列表排序中,后两中方法还可以加入条件参数进行排序。 reverse()方法 将列表中元素反转排序,比如下面这样 >>> x =...
-

Python中使用urllib2模块编写爬虫的简单上手示例
这篇文章主要介绍了Python中使用urllib2模块编写爬虫的简单上手示例,文中还介绍到了相关异常处理功能的添加,需要的朋友可以参考下 提起python做网络爬虫就不得不说到强大的组件urllib2。在python中正是使用urllib2这个组件来抓取网页的。urllib2是Python的一个获取URLs(Uniform Resource Locators)的组件。它以urlopen函数的形式提供了一个非常简单的接口。通过下...
-

Python模拟百度登录实例详解
最近公司产品和百度贴吧合作搞活动,为了增加人气,打算做个自动签到的小程序,接下来通过本文给大家介绍python模拟百度登录,感兴趣的朋友一起学习本段代码吧 最近公司产品和百度贴吧合作搞活动,为了增加人气,打算做个自动签到的小程序。这个是测试登录的代码,写的比较随意,仅实现了登录并读取关注贴吧列表,下边的就比较简单。 百度登录还是有点麻烦的,由于用的ssl,所以要先获取token,然后再登录,这个用finddle2分析下,还是比...
-

Python的Scrapy爬虫框架简单学习笔记
这篇文章主要介绍了Python的Scrapy爬虫框架简单学习笔记,从基本的创建项目到CrawlSpider的使用等都有涉及,需要的朋友可以参考下 一、简单配置,获取单个网页上的内容。 (1)创建scrapy项目 scrapy startproject getblog (2)编辑 items.py # -*- coding: utf-8 -*- # Define here the models for...
-
使用Python编写爬虫的基本模块及框架使用指南
这篇文章主要介绍了使用Python编写爬虫的基本模块及框架使用指南,模块介绍包括了urllib和urllib2以及re的使用例子框架则是Scrapy的简介,需要的朋友可以参考下 基本模块 python爬虫,web spider。爬取网站获取网页数据,并进行分析提取。 基本模块使用的是 urllib,urllib2,re,等模块 基本用法,例子: (1)进行基本GET请求,获取网页html #!coding=ut...